‘Tis the season to be controversial, so let’s take a stroll down memory lane to Ken Henderson’s classic Inside the SQL Server 2000 User Mode Scheduler:
The waiter list maintains a list of workers waiting on a resource. When a UMS worker requests a resource owned by another worker, it puts itself on the waiter list for the resource and enters an infinite wait state for its associated event object. When the worker that owns the resource is ready to release it, it is responsible for scanning the list of workers waiting on the resource and moving them to the runnable list, as appropriate. And when it hits a yield point, it is responsible for setting the event of the first worker on the runnable list so that the worker can run. This means that when a worker frees up a resource, it may well undertake the entirety of the task of moving those workers that were waiting on the resource from the waiter list to the runnable list and signaling one of them to run.

The lists behind the legend
I have not gone as far as opening up my rusty copy of SQL Server 2000 to see how Ken’s description fits in there, but I am now pretty certain that the above quote has transmuted over the years into a common misunderstanding about SQLOS scheduling mechanics.
Now nothing Ken said is untrue or particularly out of date. It is just that we often hear “the waiter list” (by implication handling resource waits) described as an attribute of a scheduler, which is not the case.
Let’s revisit when the scheduler code runs, and what it does:
- A worker will yield, either because it needs to wait for a resource, or because it is eaten up with guilt over reaching the end of its allotted quantum.
- The act of yielding means that scheduler code (methods on the SOS_Scheduler class) gets invoked.
- After a bit of housekeeping for the common good of all workers sharing the scheduler, control is transferred back to a worker to do its thing – this may even be the same worker who originally yielded.
- The housekeeping consists of checking for aborted tasks, processing pending I/Os, and checking for I/O completions and timer list timeouts.
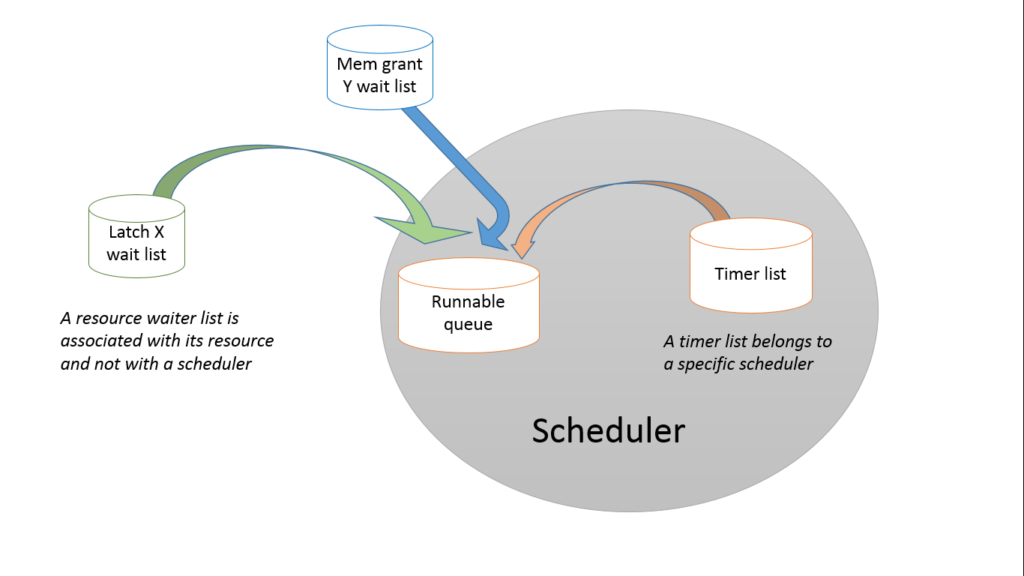
The single most important list that a scheduler owns is the collection of runnable workers, that is, the subset of workers belonging to this scheduler who are not waiting for anything other than CPU. This has variously been described as a list and a queue; I shall be using the term “runnable queue” by convention, but be aware that it is a data structure that has changed over the years and isn’t a simple queue.
A scheduler has one piece of “creative” interaction with this runnable queue, and it comes with only two variables:
- When a context switch is requested by an outgoing worker owning the scheduler, the scheduler code has to choose which one of potentially multiple workers is going to be its next owner.
- The incoming worker gets given a quantum expiry date, by which time it is expected to yield.
Core scheduler code running during context switching only dequeues runnable workers, and at such moments a given scheduler only looks at its own runnable queue. In contrast, code running all over the place, including in the context of workers belonging to other schedulers, may enqueue workers on to the runnable queue.
Time for a simple diagram:
Someone to watch over me
What I’m trying to get across here is that each instance of a waitable resource has its own wait list, and the scheduler has no interest in this, because a scheduler only acts upon its runnable queue. Seen from a different angle, once a worker is waiting on a resource, its scheduler doesn’t care, because it can’t and won’t manage the waiting logic of something like a latch. This splits the responsibilities neatly in two:
- The synchronisation class guarding a resource (which inevitably will be built upon an EventInternal) stands watch over all the workers queueing up to have a ride on that resource. The act of granting access to a worker involves moving the worker from the wait list and getting it on to the runnable queue of that scheduler’s worker, and this is achieved by the synchronisation class.
- The scheduler, in turn, doesn’t decide who is runnable, but it does get to pick which of the runnable workers (however they reached that state) runs next.
The I/O and timer lists
There are however two cases where the scheduler decides to make a worker runnable in the normal course of events. One is when a worker was waiting on I/O to complete, where periodic scheduler housekeeping is the mechanism by which SQLOS takes note of the I/O completion. At this point some workers who were on the I/O list may find themselves moved to the runnable queue just before the next worker is picked to be granted ownership of the scheduler – the lucky winner might be one of these workers, or it may be someone else who has been runnable for a while.
The second, and actually more interesting case, is the timer list. In its simplest use case, this is where you will find workers executing T-SQL WAITFOR statements. The list is neatly ordered by timer expiry date, and at each invocation of the scheduler context-switch housekeeping, workers whose timer expiry dates have now passed will be moved to the runnable queue.
What makes a timer list particularly interesting though, is when it implements a resource wait timeout, for instance a lock timeout. In this scenario we actually have a worker waiting on two things simultaneously: a resource and a timer. If the resource is acquired before the timer expires, all is good: the worker goes on to the runnable queue, and upon being woken up it finds a thumbs-up as the return value of its resource acquisition call.
However, should the timer expire before the resource has been acquired, the scheduler will actually venture forth and take the worker off that waiter list before making it runnable and setting an error return value as wake-up call. Think of it as every teenager’s worst nightmare: you’re not home by curfew, so Mom comes to your dodgy party to drag your sorry ass home. And then you wake up with a hangover and note stuck to your forehead reading “No cake for you”.
Whither next?
I tried to keep this comparatively high-level, but might take a nice little detour into the WorkerTimerRequest some day if time permits.
There you have it. Be home on time and have a thread-safe festive season.