
This is part 2 in a series exploring ways in which a chunk of running SQL Server code gains context, i.e. the mechanisms by which a bunch of instructions get to participate in something bigger and just possibly a bit unpredictable. You can find part 1 here. (Update: and now there is also part 3.)
Today’s instalment on the use of the stack may come across as rather obvious or perhaps “computer science-y”, so I’m going to try and sweeten the deal by using small but perfectly nuggets of complete SQL Server functions to illustrate some detail. Detail there will be aplenty, so feel free to skim-read just to get the aroma – that is probably what I would have done if I were in your aromatic shoes. Special thanks to Klaus Aschenbrenner (b1 | b2 | t) for recently filling in a bothersome gap in my knowledge by pointing me to this great resource.
Stacks revisited
Refresher time. In its strict sense, a stack is a LIFO data structure where all interaction occurs through push (insert item at the end) or pop (remove item from that same end) operations. By its nature, a stack grows and shrinks all the time while in use, and it can’t get internally fragmented by having chunks of unused space.
When we talk about “the stack” in Windows, we normally mean the user-mode stack of a specific thread. As functions call each other, the last thing done before transferring control to the callee is to push the address of the next instruction (the return address) on to the stack. Once the callee is finished, the act of returning involves popping that address into the instruction pointer, which transfers control back to the expected point within the caller. Note that this implies a strict requirement for symmetric management of the stack within each function: one push or pop too many, and the control flows goes haywire.
Additionally, the thread stack provides a convenient place to store local variables, within reasonable memory usage limits. The natural flow of stack allocation and cleanup is a perfect fit for variables whose lexical scope and lifetime are restricted to the function invocation.
Every invocation of a function gets its own stack frame. In its most rudimentary form, it consists of only the return address, but it can get arbitrarily big (within reason) as space is allocated for saved registers and local variables. Generally speaking, a function should only work with stack memory within its own stack frame, i.e. on its side of that return address, and anything beyond that has the smell of malicious interference. Special exceptions exist for access to stack-passed parameters and (in the Windows x64 convention) to the shadow space described later. Additionally, a pointer passed from a parent function to a child for an output parameter may very well refer to stack-allocated memory within the parent, and the child can end up legally writing into the stack frame of the parent – after all, as long as it follows good hygiene and doesn’t play buffer overrun games, it shouldn’t care where an output parameter points to.
Traditionally, stacks grow downward in memory, i.e. they start at a high address, with a push operation decrementing the stack pointer, and a pop incrementing it. I tend to visualise high memory addresses as being near the top of a printed page. However, when representing a call chain, standard current usage puts the high memory at the bottom of the page, i.e. the stack grows visually upward.
Whatever language you program in, chances are your compiler does the honours of sorting out the details and not letting you shoot yourself in the foot by corrupting the stack. So this isn’t something where you are normally exposed to the mechanics, unless you look at it from the low-level perspective of assembler code emitted by the compiler.
Calling conventions: the 32-bit vs 64-bit divide
Before getting into details of mechanism, I should point out that stack usage is an area where 64-bit Windows code looks entirely different from 32-bit equivalents. A lot of excellent older resources are 32-bit specific, but I restrict myself to the 64-bit world here.
Specifically, the 32-bit world had quite a number of competing calling conventions, notably cdecl, stdcall, and fastcall. 64-bit Windows specifies a single Application Binary Interface (ABI) based on the old fastcall. This favours parameter passing through registers and thus gets away with much less stack usage, which is a performance bonus, since register accesses are a lot faster than memory access, even disregarding cache misses. Be that as it may, it still makes sense to remember the central position of the stack in function calls.
Leaving aside floating point and SIMD registers, the convention is fairly simple:
- Parameter 1 goes in the rcx register
- Parameter 2 goes in rdx
- Parameter 3 goes in r8
- Parameter 4 goes in r9
- Further parameters are pushed onto the stack from right to left (standard C convention, which allows for variable number of parameters since the first one will be in a known place)
- The function’s return value goes in rax
Additionally, the caller of a function must leave 32 bytes free for the callee’s use, located just before (above) the return address. All functions get this scratchpad – known variously as “shadow space” or “parameter homing space” – for free, but only functions which call child functions need to worry about doing this little allocation. Think of it as a memory nest egg.
Finally, while 32-bit code had the freedom to push and pop to their hearts’ content, such adjustment of the stack pointer is now only allowed in a function’s prologue and epilogue, i.e. the very first and very last bit of the emitted code. This is because of another very important convention change. In the 32-bit world, a function always saved the initial value of the stack pointer in the EBP register after pushing the old value of EBP, and this allowed for traversal of the call chain. Such traversal is needed for structured exception handling, as well as for diagnostic call chain dumps, such as the ones we sometimes get exposed to in SQL Server.
However, the mechanism for finding one’s way in the call stack now relies on metadata in the 64-bit world: if something goes wrong while the instruction pointer is at address 0x12345, it is possible for exception dispatching code to know what function we’re in from linker/loader metadata alone. This then allows an appropriate Catch block within the function to be called. And if the exception is uncaught and needs to bubble up? Well, since the stack allocation size of the function is part of that metadata, and the stack pointer doesn’t change during the function body, we can just add a constant to the current stack pointer to find the return address, hence deduce who the caller was, continuing the same game.
Note that all this describes a set of Windows conventions. However, this is still at a level where SQL Server on Linux plays by the Windows rules, up to a certain point within SQLPAL.
A word on Assembler examples
I picked four short SQL Server functions, in gently increasing level of complexity, to illustrate stack frames, finished with the prologue of a bigger function. When you dump functions in Windbg using the uf command, e.g. uf sqllang!CSecContextToken::GetImpersonationAttr, the output includes addresses as loaded, the hexadecimal representation of the instructions, and the human-readable Assembler, for instance:
sqllang!CSecContextToken::GetImpersonationAttr: 00007ffb`ee7e8b80 488bc1 mov rax,rcx 00007ffb`ee7e8b83 488bca mov rcx,rdx 00007ffb`ee7e8b86 41b838000000 mov r8d,38h 00007ffb`ee7e8b8c 488d9088110000 lea rdx,[rax+1188h] 00007ffb`ee7e8b93 e9a886ffff jmp sqllang!memcpy (00007ffb`ee7e1240)
To remove irrelevant noise, I have stripped my examples down to just the bare Assembler, removing address references except in one place where I substituted the target of a conditional jump with a simple symbol.
Then, to address the elephant in the room: Assembler is verbose but simple. There are only a handful of instructions that do most of the heavy lifting here:
- mov dest, source is a simple assignment. Mentally read as “SET @dest = @source”. Square brackets around either operand indicates that we’re addressing a memory location, with the operand designating its address.
- lea (load effective address) is essentially a more flexible version of mov, although the square brackets are deceptive: it never accesses memory.
- push decrements the stack points (rsp) and then writes the operand at the memory location pointed to by the modified rsp.
- pop copies the value at the memory location pointed to by rsp into the operand, and then increments rsp.
- add operand, value and sub operand, value respectively adds or subtracts the supplied value from the operand.
- jmp is an unconditional jump, loading the instruction pointer with the supplied address (note that symbols are just surrogates for addresses). je (jump if equal/zero) is one of a family of conditional jumps.
- call does the same as jmp, except that the jump is preceded by first pushing the address of the next instruction (after the call) onto the stack.
Don’t sweat the details, I’ll explain as we go along.
Example 1: no stack manipulation in function
Here we have a function that looks like a straightforward property accessor. It takes one parameter in rcx, which the caller populated, and it is a reasonable assumption that it will be the “This” pointer for a class instance. Certainly it is a pointer to a memory address, because we dereference the (32-bit) doubleword that is 0x1188 bytes away to come up with a return value.
sqllang!CSecContextToken::GetImpersonationType: =============================================== mov eax,dword ptr [rcx+1188h] ret
So what does the stack frame look like? Well, by definition the function call gave us the 32-byte shadow space, although we don’t end up using it, and this is followed by the return address. Within this function, nothing uses the stack except the act of returning.
Nice and simple. From the viewpoint of the rsp value, the bit of the stack we are allowed to take an interest in looks like this:
- rsp + 0x20 – shadow space
- rsp + 0x18 – shadow space
- rsp + 0x10 – shadow space
- rsp + 0x8 – shadow space
- rsp – return address
How things got set up to be this way isn’t any concern of this function.
Example 2: child function as tail call
The next example features a child call to the standard C library memcpy function. However, since this is the very last thing the function does, we see a so-called tail call optimisation: there is no need to call this function for the sake of it returning to nothing more than a ret instruction. By directly jmping to it, we get the same functionality with fewer instructions and fewer memory accesses, and since we’re done with the shadow space, the child can inherit ours. The return address seen by memcpy() isn’t its caller, but its caller’s caller, and that is all fine and dandy.
sqllang!CSecContextToken::GetImpersonationAttr: =============================================== mov rax,rcx mov rcx,rdx mov r8d,38h lea rdx,[rax+1188h] jmp sqllang!memcpy
This stack frame has the same structure as the previous example, although more non-stack parameters come into play in the child function call. Let’s explore them for laughs.
memcpy() has a well-documented signature, and we can simply look up the parameter list, all of which fit into the pass-by-register convention:
- *destination goes in rcx. The assignment “mov rcx, rdx” tells us that this is in fact the second parameter passed to GetImpersonationAttr() – or the first explictly passed parameter after an implicit *This – so we immediately know that GetImpersonationAttr() takes a parameter of a pointer to the target where something needs to be copied, i.e. an output parameter.
- *source goes in rdx, and is supplied as the same 0x1188 offset into *This as the previous function, and now we know that the first four bytes of the impersonation attribute structure is in fact the impersonation type. Whatever that means 🙂
- num goes into r8d (the lower 32 bits of r8), so clearly the impersonation attribute structure has a size of 0x38 bytes.
Fun fact about tail call optimisation. Textbook explanations of simple recursive functions often work on the premise that you’ll overflow the stack beyond a certain recursion depth. However, many practical recursive functions, including the hoary old factorial example, can have the recursion optimised away into tail calls. The functional programming folks get all frothy about this stuff.
Example 3: stack parameters and child function
In this function, we come up against the need for local storage, meaning a stack allocation is required. This couldn’t be simpler: just pull down the Venetian blind of the stack pointer and scribble on the newly exposed section. Or more concretely, decrement the stack pointer by the amount you need.
This example also involves more than four incoming parameters, hence some will be passed on the stack. And the nature of the function is that it is really just a wrapper for another function, and must pass those same parameters through the stack for the child function. This then also brings the responsibility or pulling down the stack pointer by an extra 32 bytes to provide shadow space for the child function.
Here goes – I added line breaks around pairs of related assignment instructions.
sqllang!CSecContextToken::FGetAccessResult: =========================================== sub rsp,68h mov rax,qword ptr [rsp+0C0h] add rcx,12A0h mov qword ptr [rsp+50h],rax mov rax,qword ptr [rsp+0B8h] mov qword ptr [rsp+48h],rax mov rax,qword ptr [rsp+0B0h] mov qword ptr [rsp+40h],rax mov rax,qword ptr [rsp+0A8h] mov qword ptr [rsp+38h],rax mov eax,dword ptr [rsp+0A0h] mov dword ptr [rsp+30h],eax mov eax,dword ptr [rsp+98h] mov dword ptr [rsp+28h],eax mov eax,dword ptr [rsp+90h] mov dword ptr [rsp+20h],eax call sqllang!CTokenAccessResultCache::FGetAccessResult add rsp,68h ret
Let’s get the register usage out of the way first: although four of them are invisible in the code, we can infer their presence through convention:
- rcx is adjusted before being passed to the child. Assuming that these are both instance methods, this suggests that the CTokenAccessResultCache instance is 0x12A0 bytes into CSecContextToken.
- rdx, r8 and r9 are passed straight through to the child function. We can’t tell from this code whether they use the full 64 bits or perhaps only 32, but this would be made more clear from examining the caller or the child.
- rax is used as a scratch variable in indirect memory-to-memory copies – such copies can’t be done in a single CPU instruction. However, assuming the child function has a return value, it will be emitted in rax, and that will go straight back to our caller, i.e. the parent inherits the child’s return value.
- No other general-purpose registers are touched, so we don’t need to save them.
Boring arithmetic time. What happens here is that seven parameters beyond the four passed in variables get copied from the caller’s stack frame to the child parameter area of our stack frame. The parent saved them at its rsp + 0x20 upwards; with the interposition of the return address, it is our rsp + 0x28 upwards, and then after adjusting rsp by 0x68 it becomes rsp + 0x90 upwards. We dutifully copy them to our rsp + 0x20 upwards, which the child function will again see as rsp + 0x28 upwards.
One interesting sight to call out is the rcx adjustment squeezed in between the “from” and “to” halves of the first parameter copy. This is not messy code, but a classic tiny compiler optimisation. Because two consecutive memory accesses lead to memory stalls, the compiler will attempt to weave non-memory-accessing instructions among these memory access if possible. Essentially we get that addition for free, because it can run during a clock cycle when the memory instruction is still stalling, even in cases where the literal expression of the source code logic suggests a different execution order.
A more interesting observation is that all this allocation and copying is just busywork. For whatever reason, the compiler didn’t or couldn’t apply a tail call optimisation here. If it did, the child function could just have inherited the parent’s parameters, apart from the rcx adjustment, yielding this three-liner:
sqllang!CSecContextToken::FGetAccessResult: =========================================== add rcx,12A0h jmp sqllang!CTokenAccessResultCache::FGetAccessResult ret
Example 4: two child functions and saved registers
This doesn’t add much complexity to the previous one, and is a more straightforward read, although it introduces a conditional branch for fun. Hopefully my ASCII art makes it clear that control flow after the je (jump if equal, or in this case the synonym jump if zero), can either continue or skip the second child function call.
sqllang!CSecContextToken::`vector deleting destructor':
=======================================================
mov qword ptr [rsp+8],rbx
push rdi
sub rsp,20h
mov ebx,edx
mov rdi,rcx
call sqllang!CSecContextToken::~CSecContextToken
test bl,1
+-+- je LabelX
| |
| | { if low bit of original edx was set
| -> mov rcx,rdi
| call sqllang!commondelete
| }
|
LabelX:
+--> mov rax,rdi
mov rbx,qword ptr [rsp+30h]
add rsp,20h
pop rdi
ret
The rdi register is used as a scratchpad to save the incoming rcx value for later – first it is used to restore the possibly clobered rcx value for the second child function call, and then it becomes the return value going into rax. However, since we don’t want to clobber its value for our caller, we first save its old value and then, at the very end, restore it. This is done through a traditional push/pop pair, which in x64 is only allowed in the function prologue and epilogue.
Similarly, ebx (the bottom half of rbx) is used to save the incoming value of the second parameter in edx. However, here we don’t use a push/pop pair, but instead save it in a slot in the shadow space. Why two different mechanisms for two different registers? Sorry, that’s one for the compiler writers to answer.
Example 5: The Full Monty
This example is from a much meatier function – somewhere north of 200 lines – so I’m just going to present the prologue and the very beginning of the function proper. For the sake of readability, I’m again adding a few line breaks around related chunks of instructions.
sqllang!CStatement::MkShowplanRow: ================================== push rbp push rsi push rdi push r12 push r13 push r14 push r15 lea rbp, [rsp-1Fh] sub rsp, 0E0h mov qword ptr [rbp-19h], 0FFFFFFFFFFFFFFFEh mov qword ptr [rsp+138h], rbx mov rax, qword ptr [sqllang!_security_cookie] xor rax, rsp mov qword ptr [rbp+17h], rax mov qword ptr [rbp-61h], r9 mov r15, rdx mov qword ptr [rbp-31h], rdx mov r13, rcx lea rax, [sqllang!CShowplanString::`vftable'] mov qword ptr [rbp-51h], rax xor eax, eax mov qword ptr [rbp-49h], rax ...
This has a lot more going on, so to save our collective sanity I have prepared a table of stack offsets relative to rsp at function entry, rbp, and the adjusted rsp. Note that the Local Variables section covers a lot of real estate, but I only listed the first few slots. This picture should drive home the notion of why we talk about a stack “frame”: it is a chunk of memory serving as the frame for a single invocation of a function, as is itself the feaming context for subservient sections.
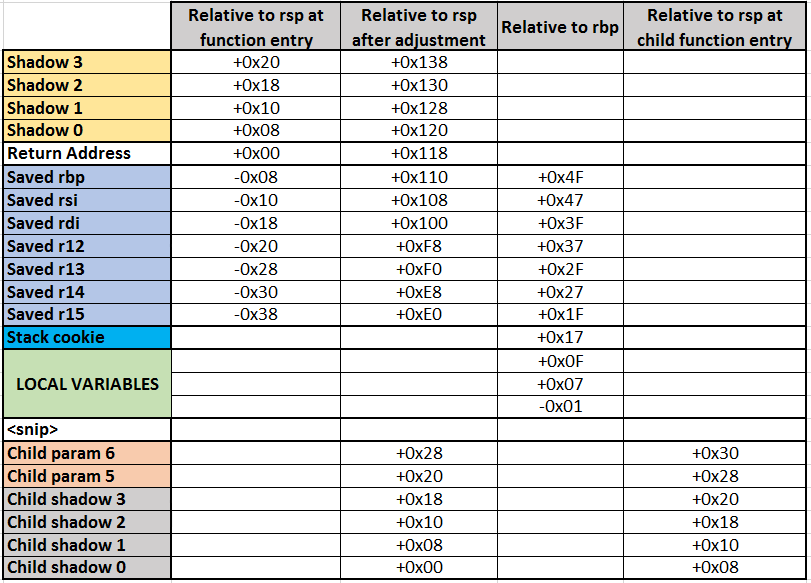
For unknown reasons, rbp comes into play here. This is odd, because its value relative to rsp is constant, and all rbp-relative memory references could have been expressed just as easily by making them rsp-relative. Even more mysteriously, the compiler decides that an unaligned (non divisible by 8) offset is just the ticket. Having said that, it doesn’t change anything from a functional viewpoint; it just means that the arithmetic looks more weird.
I’m not going to do this one line by line, because you can translate things fairly easily using the table as a crutch. If I leave you with the general feeling that those translated angry bracket numbers can be coaxed into something sensible, I have achieved a lot.
So let’s just wrap up with a few highlights:
- The local variable at [rbp-19h] receives what appears to be a very large number. Or if you consider it signed (see here for more signed integer gossip), it’s just the value -2. The presence of this variable is is very common in the SQL Server code base, and presumably is part of some convention.
- The value of rbx is again saved in the shadow area, while the parameter-carrying registers r9 and rdx get saved lower down in the stack among the rest of the local variables. rcx gets backed up in a register of its own (r13), and rdx goes to r15 in addition to that stack backup. Why both? Again, a compiler quirk.
- The value written to [rbp 0x17] is a stack cookie, used as a safety mechanism to detect stack corruption. By its nature, it is an unpredictable value, and when its value is re-checked at the end of the function, detected corruption can be dealt with as an exception.
- The assignment of a vftable address to a memory location in the local variable area (line 27), followed by a bunch of further zero-value initialisations of subsequent addresses, is a dead giveaway that we’re constructing a temporary instance of a class with virtual functions, in this case a CShowplanString.
Conclusion and further reading
Gosh, that sure was more detail than I was expecting. And welcome to the end of the post.
I’ll let Gustavo Duarte have the last word again. Thrice.
- Journey to the stack is an excellent coverage of the stack in general. Just be aware that it is 32-bit focused.
- Epilogues, Canaries and Buffer Overflows looks into how a runtime can protect the stack against exploits.
- Tail Calls, Optimization, and ES6 tells you more than you ever thought you wanted to know about tail calls.
2 thoughts on “Context in perspective 2: A pretty stack frame is like a melody”