
Following hot on the heels of sys.dm_os_threads, today we look into the worker objects built on top of them. This is intended to be supplementary to the official documentation on sys.dm_os_workers, so I’ll comment on that where appropriate, rather than repeating it. My reference version is 2016 SP1.
Basic plumbing of related objects
worker_address is of course simply the address of the Worker class instance we’re looking at. It is bound to the SOS_Scheduler living at scheduler_address and (once out of the SystemThreadDispatcher) to the SystemThread class instance at thread_address.
Once bound to an SOS_Task in the owning scheduler’s WorkDispatcher, it will expose that object’s address in task_address.
If we’re running in fiber mode, fiber_address points to the fiber data containing the user-mode thread state.
Now this isn’t intended to be about memory, but memory issues tend to touch everything we look at anyway, so a short diversion is in order.
We saw in my previous post on sys.dm_os_threads that each thread gets an associated MiniSOSThreadResources object which already contains a worker. Beyond that initial thread bootstrapping though, the factory method Worker::CreateWorker() is called to create useful Workers. One of the first things that function does is to allocate the memory (2816 bytes) in which to construct the Worker instance. This memory is provided by a memory object which is specially created for the occasion, and the pointer to the memory object is stored within the Worker; this is what gets exposed as memory_object_address.
What’s interesting in the memory hierarchy is that this is a memory object which both “belongs” to the Worker and is its parent. It is possible for other objects and functions to milk it for further “worker-local” allocations, although that would be an exploration for another day.
State and status
The state enum is a familiar one; here are its integer values:
0 - Init 1 - Running 2 - Runnable 3 - Suspended
As described in The DMV diaries: Task, Request and Session State, the value exposed in the DMV lacks the layered semantics of e.g. task state. Once we go beyond Init, we simply see how the SQLOS scheduler views the worker when in nonpreemptive mode. If the worker is running, it owns the scheduler. If runnable it is owned by the scheduler’s runnable queue. And if suspended, the scheduler doesn’t have any interest in its movement, unless the worker is waiting on IO or a timer.
status is an interesting one, and is the source of a bunch of the following is_xxx flags, which break out its individual bits.
Here is the 0-based bit mapping of the flags exposed in the DMV, plus a handful of others I know to be in use but aren’t exposed here.
bit 2 - is_preemptive bit 3 - is_fiber bit 4 - is_sick bit 5 - is_in_cc_exception bit 6 - is_fatal_exception bit 7 - is_inside_catch bit 8 - also involved in exception state bit 11 - used in scheduling bit 12 - lazy preemptive (in conjunction with 2) bit 13 - is_in_polling_io_completion_routine bit 19 - set in SOS_Task::DoomThread()
There is a second bitmask member in the Worker class, containing flags like “do not suspend”, “is in external code”, “is in exception backout” etc. For whatever reason, the DMV authors didn’t expose any of these flags.
I/O, exception and affinity metrics
pending_io_count is a straightforward member of the Worker instance, as is pending_io_byte_count. And pending_io_byte_average is simply a convenience column derived from the other two, saving you from having to special-case around potential division by zero.
It is possible for exception_num to be either a 16-bit or 32-bit integer; which it is is determined by another flag elsewhere in the worker. exception_severity lives within the worker, but additional information like exception state is found in a separate ExceptionInfo struct, which is the thing pointed to by exception_address.
affinity comes straight from a Worker member, whereas processor_group is derived from an embedded NodeAffinity instance.
Timestamps
Time to talk about time again. Within SQLOS, the vast majority of “Now()” time stamps are stored as integers sourced from one of two domains. Which domain gets used is determined at service startup and – to the best of my knowledge – will not change until shutdown. The two option are:
- The QueryPerformanceCounter (QPC), used if an invariant timestamp is available. This is the more predictable and finely grained option, and I’d assume that it applies on most serious systems.
- As fallback, timer interrupt ticks can be used. These are very easy and cheap to retrieve from the KUSER_SHARED_DATA structure, but resolution is at the mercy of outside forces, and can be as bad as 15.6ms.
I have previously touched on the two options when discussing the source of getdate() in Milliseconds 10, ticks 3.
So to get to the point, all the below columns expose normalised values, derived either by applying the instance-specific SOS_PublicGlobals:sm_QueryPerformanceFrequencyBase (QPC) or a simple constant factor of 10,000 (interrupt ticks) to the underlying properties:
- worker_created_ms_ticks
- task_bound_ms_ticks
- wait_started_ms_ticks
- wait_resumed_ms_ticks
- start_quantum
- quantum_used
- max_quantum
Here are a few notes to pad out the official documentation.
wait_started_ms_ticks is set in SOS_Task::PreWait(), i.e. just before actually suspending, and again cleared in SOS_Task::PostWait(). For more about the choreography of suspending, see here.
wait_resumed_ms_ticks is set in SOS_Scheduler::PrepareWorkerForResume(), itself called by the mysteriously named but highly popular SOS_Scheduler::ResumeNoCuzz().
start_quantum is set for the Resuming and InstantResuming case within SOS_Scheduler::TaskTransition(), called by SOS_Scheduler::Switch() as the worker is woken up after a wait.
max_quantum is a high-water mark for the longest time the worker has spent on a single quantum, and quantum_used is the total time the worker has spent in the Running state.
Definitely the most interesting one of the bunch is end_quantum. This is a calculated field, and is simply start_quantum plus the scheduler’s quantum length, which is currently always 4ms.
What makes it interesting is that this calculation is redundant with the quantum target actually stored as a property within the Worker. This has been touched on recently by Paul Randal in a great thought-provoking blog post when he mentioned that the quantum end is stored in RDTSC ticks.
My best guess is that RDTSC came to the fore here for the sake of fine grain and very low cost. Even in the face of clock speed changes, having a bit of variation in the quantum end is probably no big deal, compared with the risk of having to use interrupt ticks with a dodgy or completely unusable accuracy. And on the cost front, the classic “is it time to yield yet?” check is really cheap to express when it’s just a case of pulling up the current TSC and comparing it with the precalculated finish line.
Anyhow, when calculating end_quantum for the DMV, we get the additional conversion joy of leaning on SOS_PublicGlobals::sm_CpuTicksPerMillisecond, because the quantum length (at scheduler level) is expressed in CPU ticks.
Odds and ends
last_wait_type, tasks_processed_count and signal_worker_address are fairly straightforward.
context_switch_count is incremented within SOS_Scheduler::TaskTransition() in three of its cases:
- Suspending, the normal case where a worker is about to be switched out.
- InstantResuming, where the quantum was exhausted but the runnable queue is empty, so the worker gets another quantum without any switch actually taking place.
- SwitchToNonPreemptive, where a preemptively scheduled worker rejoins the cooperative ecosystem.
The return_code property shows up the mechanism by which results of asynchronous calls propagate back to the calling worker. Whoever makes the waiting worker runnable again (typically return of a wait function), the result of the wait is written into this member while the worker remains asleep. After getting back to the runnable queue, and eventually being picked as the next worker to run, SOS_Scheduler::Switch() reads this value and returns it as the return value to the awakened worker. This may propagate through a few layers of function calls, but ultimately it will reach a function that will know what to do with it, e.g. turn a timeout result into an exception.
boost_count is an oddity for dragging a rather useful explanation of priority boosting into the official documentation. Here is my best effort at making sense of this mechanism, whereby a thread waiting on a synchronisation object gets bumped to the head of the runnable queue 1000 times in a row, but then going to the back once before being eligible for a boost again.
The idea of applying a priority boost is a familiar one from OS scheduling. This serves to avoid the priority inversion that can be caused in the below scenario:
- Many threads wait for a resource
- The low priority thread eventually gets its turn, is assigned ownership and made runnable, while others (including high-priority ones) are waiting in line behind it
- Because it has low priority to the scheduler, it doesn’t get scheduled
- Now the higher priority threads don’t get to run either, because they are waiting on something that won’t get to run and pass the baton to them
While the boosting mechanism does apply as described, we are glossing over the fact that each scheduler’s “runnable queue” may actually consist of a lot of different queues. The detail has changed between 2014 and 2016, but the omitted bit still boils down to this: Upon becoming runnable, a worker gets a place at the head or the tail of its assigned queue, but this mechanism doesn’t affect what queue it goes into. In the face of workload groups, it might still be possible to craft priority inversion.
DMV data source and iteration mechanism
Good news. This one is a lot more simple and obvious than sys.dm_os_threads, although with a nice twist that made me rethink the object ownership hierarchy.
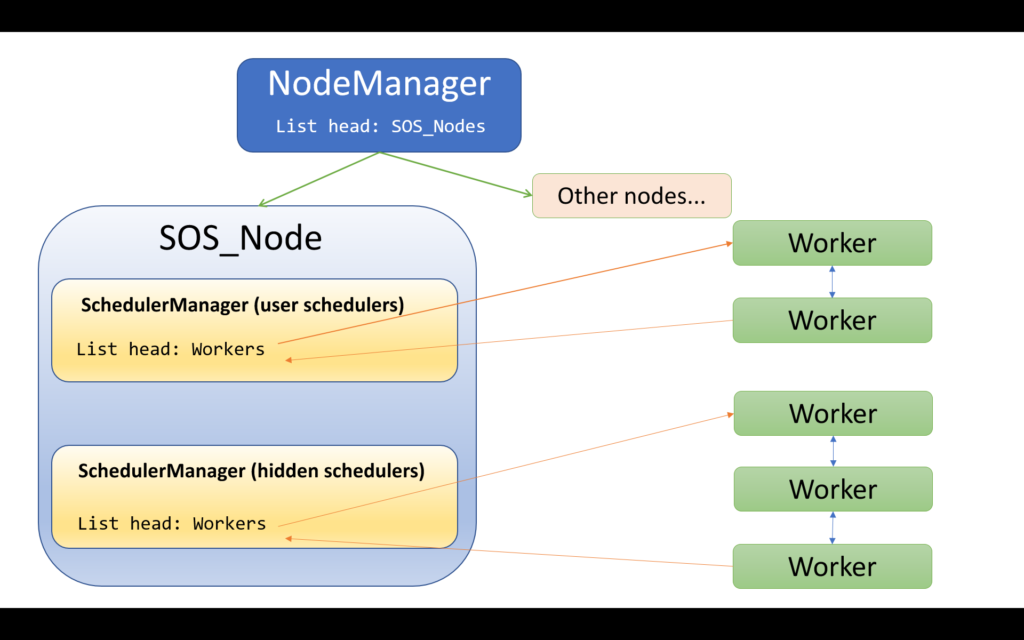
There isn’t a single global list of all Workers, so we start at the root of all things, the singleton NodeManager, to iterate over all SOS_Nodes. Now on a per-node basis, we indirectly find a way to iterate over Workers associated with that node.
It turns out that while workers are associated with schedulers, the relationship works one-way, and schedulers don’t keep lists of their workers, apart from the suspend queues that live within the scheduler (timer lists, IO lists, runnable queues). However,taking one step up in the hierarchy, we do find such a list in the SchedulerManager.
This makes sense when you consider that a worker starts its life being suspended in a SystemThreadDispatcher, which itself lives in a SchedulerManager with a 1:1 relationship between them. The linked list item (right at the start of the Worker object) which enlists it into the SystemThreadDispatcher is the suspend queue entry, and this is the one which moves between different suspend queues, or which belongs to no list at times when the worker is running. There is however a second linked list entry sixteen bytes into the Worker; this one’s list head is in the SchedulerManager.
Each node contains separate SchedulerManagers for normal and hidden schedulers, so the full iteration pattern for the global worker iterator goes like this:
- Start with the NodeManager
- Iterate over all the SOS_Nodes
- Per SOS_Node, first iterate over the workers belonging to its “regular” SchedulerManager
- When done with these, now iterate over workers belonging to the “hidden” SchedulerManager
Here is an outline of the involved objects.
The mechanism of engaging with a retrieved Worker is less clunky than is the case for dm_os_threads, which requires the target objects to be cloned while locked. Workers have their lifetimes controlled by reference counting, so upon finding the next worker, the reference count on the worker is increased before releasing the list’s spinlock. This avoids the worker getting destroyed while we are querying it. Upon moving to the next worker, the reference count on the previous one is decremented, and – in keeping with the reference-counting contract – if this was the last reference, the worker is then destroyed and its memory deallocated.
Well, there you have it for workers. Who can tell where we’ll go next?
Holy cow! I’ve read this post so many times and always thought “spinlock” for “synchronization object”! But now I’m running into massive latch_ex waits for NESTING_TRANSACTION_FULL and thinking: hey! I bet that exclusive latch is a “synchronization object”. If so, assuming multiple workers on a given scheduler are trading this latch with other workers on other schedulers… i bet those workers could start trading off unfair boosted execution time between them. And other workers waiting for resources held by the worker getting squeezed out could suffer.
Gotta add boost_count to my monitoring to see if that’s happening.
Ahhh. Well. If only i remembered the things i’d learned from you in the past 🙂
Yep, I bet the latch_ex waits for NESTING_TRANSACTION_FULL are as bad as they are in part because of spinlock contention on the way to getting the latch.
https://sqlonice.com/latch-files-spinlock-dares-not-speak-its-name/
Cool post!
But is there a really 1-1 relationship between os_threads and os_workers?
If I run select * from sys.dm_os_threads and select * from sys.dm_os_workers the 2 queries return different list of results: there are more os_threads than os_workers! So, where is the mapping? What is the correct relationship?
Thanks
Saverio