
Like many good things, it started with a #sqlhelp question, this time from Todd Histed (b | t):
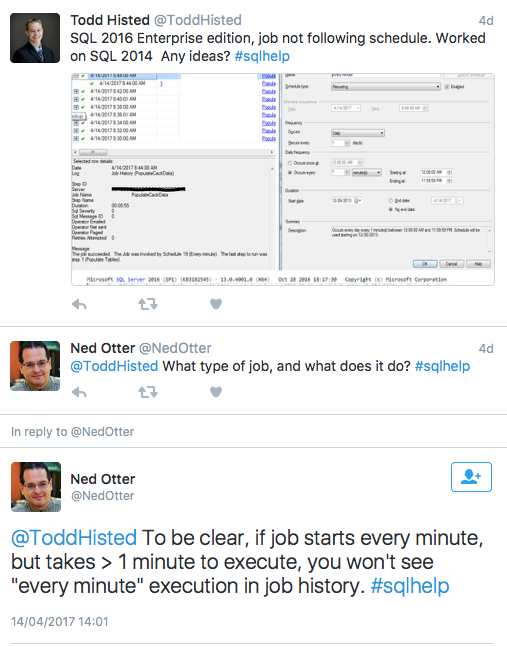
Including a bit of back and forth, the issue boiled down to this:
- A job is scheduled every minute and takes pretty much exactly 55 seconds to run, due to an included WAITFOR delay of 55 seconds
- On SQL Server 2014, this did reliably run every minute
- On SQL Server 2016, it skips minutes, effectively running only every two minutes
- Reducing the WAITFOR to 30 seconds fixed the issue
Now I get unreasonably excited both by date manipulation and by scheduling issues, so this firmly grabbed my attention. After a bit of unwarranted thinking out loud, I figured it is time to go and do some spelunking.
TL;DR
I understand: you’re a busy elf. Here is the quick summary of what I found.
Disclaimer: the different schedule types, e.g. daily vs monthly, have different special case logic; I’m just concerning myself with (intra-) daily schedules here.
Upon completion of a job, the next run time is calculated based on the last scheduled time plus the schedule interval. However, allowance is made for the edge cases where the completed invocation overruns into the next start time. In such a situation, there isn’t a “catch-up” run; instead, the schedule is advanced iteratively until it reaches a future point in time.
However, 2016 introduces a new twist. When applying the “is the proposed next schedule time after Now()?” check, it adds five seconds to Now(). In other words, the question becomes “Is the proposed next schedule time more than five seconds in the future?”
This looks more like a bug fix than a bug. Clearly cases were found where erroneous schedule invocations were happening, perhaps caused by some combination of job duration, high schedule frequency, and clock adjustments. Whatever the story, this is the behaviour we now live with going forward.
Scheduling is a notoriously tricky subject, because we tend to have an intuitive understanding of how things “ought to work,” while merrily ignoring a million little edge cases that keep developers on their toes. Just in case you needed proof.
Spelunking time
In the course of researching this, a few more fun details emerged.
Please send two mongooses
Please send two mongeese
Please send a mongoose. While you’re at it, send another.
When date and time manipulation is needed, where do you turn to? If you’re SQL Agent, this involves custom structures and functions living in SQLSVC.dll. Internally it works with date and time structures with separate 32-bit integer components for the component parts like seconds or months, but translates between this and the funky “packed decimal” pair we see persisted in tables like sysjobhistory, e.g. the integer values 20180321 and 200000 for 20h00 on 21 March 2018.
What I find really cute is the simple approach to implementing Dateadd. We get two functions here, QScheduleDateModify() and QScheduleTimeModify() to operate on such a date/time structure pair. These will only increment or decrement the structure by one tick of the specified unit, so if you want to add six hours to a time, you call QScheduleTimeModify six times with parameter values indicating Increment and Hours.
This may seem primitive, but I suppose it has the advantage of straightforward implementation: as long as overflow of your chosen unit is dealt with correctly, you never need to deal with weird questions like “how many year boundaries are crossed when I add 23,655,101 seconds to the current date?” It isn’t a generic date library, but then it doesn’t need to be. And by definition, normal calculations for schedule times don’t involve a large number of increments, so there isn’t a case for hyper-optimisation.
At this point you probably expect me to whip out Windbg. Here you go then.
Having created a job that was due to fire, I attached to the SQL Agent process, put a breakpoint on SQLSVC!QScheduleCalcNextOccurrence and waited. At the appointed hour, the job ran and the breakpoint was hit as the schedule’s next occurrence needed to get calculated.
Breakpoint 0 hit SQLSVC!QScheduleCalcNextOccurrence: 00007fff`0c0d3e20 48894c2408 mov qword ptr [rsp+8],rcx ss:0000008c`e460c240=0000008ce460c274
Just for orientation, let’s look at the call stack and the state of the CPU registers upon entry:
0:022> k
# Child-SP RetAddr Call Site
00 0000008c`e460c238 00007ff7`51595990 SQLSVC!QScheduleCalcNextOccurrence
01 0000008c`e460c240 00007ff7`51595459 SQLAGENT!SetScheduleNextRunDate+0x1f0
02 0000008c`e460c310 00007ff7`5158f992 SQLAGENT!SetJobNextRunDate+0x1a9
03 0000008c`e460c7f0 00007fff`18514f87 SQLAGENT!JobManager+0xfe2
04 0000008c`e460fc70 00007fff`1851512e MSVCR120!_callthreadstartex+0x17 [f:\dd\vctools\crt\crtw32\startup\threadex.c @ 376]
05 0000008c`e460fca0 00007fff`261913d2 MSVCR120!_threadstartex+0x102 [f:\dd\vctools\crt\crtw32\startup\threadex.c @ 354]
06 0000008c`e460fcd0 00007fff`266754e4 KERNEL32!BaseThreadInitThunk+0x22
07 0000008c`e460fd00 00000000`00000000 ntdll!RtlUserThreadStart+0x34
0:022> r
rax=000000000002ed9c rbx=0000000000000000 rcx=0000008ce460c288
rdx=000000000133c6b1 rsi=0000008cc8b23380 rdi=0000008ce428c278
rip=00007fff0c0d3e20 rsp=0000008ce460c238 rbp=0000008ce460c2a9
r8=000000000002eda1 r9=0000000000000000 r10=00000000000118a0
r11=0000000000000011 r12=0000000000000001 r13=0000000000000000
r14=0000000000000000 r15=0000000000000000
iopl=0 nv up ei ng nz na pe cy
cs=0033 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000283
SQLSVC!QScheduleCalcNextOccurrence:
00007fff`0c0d3e20 48894c2408 mov qword ptr [rsp+8],rcx ss:0000008c`e460c240=0000008ce460c274
Now whether this was C or C++ source code, the Windows x64 ABI tells us that the first parameter passed into the function lives in rcx (highlighted above). I’ll dump a chunk of memory starting at the address it points to, displaying it as 32-bit doublewords:
0:022> dd 8ce460c288 l0x20 0000008c`e460c288 00000004 00000001 00000004 00000005 0000008c`e460c298 00000000 00000000 0133c6b1 05f5bebf 0000008c`e460c2a8 00000190 000399b7 0133c6b1 0002ed9c 0000008c`e460c2b8 0133c6b1 0002ed9c 56b04598 00004634 0000008c`e460c2c8 c8b23390 0000008c 00000000 00000000 0000008c`e460c2d8 00000000 00000000 e4280400 0000008c 0000008c`e460c2e8 00000000 00000000 00000000 00000000 0000008c`e460c2f8 e428c278 0000008c e460c410 0000008c
I’ll push this along – the numbers highlighted in red are of interest. Windbg will oblige us by translating the hexadecimal representation into decimal if we ask nicely:
0:022> ? 133c6b1 Evaluate expression: 20170417 = 00000000`0133c6b1 0:022> ? 0x2ed9c Evaluate expression: 191900 = 00000000`0002ed9c 0:022> ? 05f5bebf Evaluate expression: 99991231 = 00000000`05f5bebf
Well, those kinds of numbers look more familiar, especially if you consider that the schedule fired at 19h19 on 17 April.
The rest of the experiment consisted of deliberately keeping the process frozen in the debugger for ten minutes before letting it run again; because this job was scheduled to run every five minutes, this guaranteed missing at least one run. As expected, and confirmed through a breakpoint on QScheduleTimeModify(), we went through three sets of five 1-minute increments to reach a next invocation time that was in the future.
Of course, some intent peering into assembly language was also involved, but I’ll not bore you further.
Where next?
I have a hunch that I’ll be revisiting SQL Agent at some point in the future again. However, the “Context in perspective” series is still hanging in the air, and will be picked up again. Let’s wait and see.