In my previous post I discussed the unsung early years of a SQLOS thread. Now it’s all very well knowing that threads extend themselves with SystemThreads, don Worker outfits, and execute SOS_Tasks, but I keep glossing over where tasks come from.
Gloss no more.
SOS_Task::Param – the seed of a work request
This nested struct only shows up by name in one spot on stack traces, when we see the below call as the crossover point between thread setup boilerplate and the meat of the task:
sqldk!SOS_Task::Param::Execute
This is a simple piece of abstraction, calling a previously specified function pointer with a previously specified parameter value. Those two values are the core data members of the SOS_Task::Param. In itself, such a pair is similar to the pair one would pass to a thread creation call like CreateRemoteThreadEx(). However, among the other data members we find SQLOS-specific things like a pointer to a resource group, the XEvent version of task identity and – if applicable – a parent task. These do pad out the picture a bit.
Now the SOS_Task::Param is a comparatively small structure, but it contains the core of what a task is about. Without it, an SOS_Task is a bag of runtime state without a defined mission, and isn’t “executable”. It’s just a typed block of memory: 984 bytes in the case of SQL Server 2016 SP1, of which the Param takes up 68 bytes.
Ultimately, getting a task run translates into this: Specify what you want done by phrasing it as an SOS_Task::Param, and get “someone” to create and enqueue a task based on it to a WorkDispatcher.
Which came first, the task or the task?
I have lately been spending some delightful hours unpicking the SQL Server boot process. For now, let’s stick with the simple observation that some tasks are started as part of booting. One example would be the (or nowadays “a”) logwriter task, whose early call stack looks like this:
Everything up to RunTask() is the thread starting up, getting married to a worker, and dequeuing a task from the WorkDispatcher. Apart from it being enqueued by the boot process, and the task never really completing, there is nothing special about this core piece of system infrastructure. It is just another task, one defined through an SOS_Task::Param with sqlmin!SQLServerLogMgr::LogWriter as its function pointer.
This is of course the network listener that makes it possible for us to talk to SQL Server whatsoever. It is a bit unusual in using preemptive OS scheduling rather than the cooperative SQLOS flavour, but this only affects its waiting behaviour. What makes it very special is that this is the queen bee: it lays the eggs from which other tasks hatch.
The SQL nursery
The above system tasks wear their purpose on their sleeves, because the function pointer in the SOS_Task::Param is, well, to the point. The tasks that run user queries are more abstract, because the I/O completion port listener can’t be bothered with understanding much beyond the rudiments of reading network packets – it certainly can’t be mucking about with fluent TDS skills, SQL parsing and compilation, or permission checks.
So what it does is to enqueue a task that speaks TDS well, pointing it to a bunch of bytes, and sending it on its way. Here is an example of such a dispatch, which shows the “input” side of the WorkDispatcher:
At this point, the Resource Group classifier function will have been run, and the target SOS_Node will have been chosen. Its EnqueueTaskDirectInternal() method picks a suitable SOS_Scheduler in the node, instantiates an SOS_Task based on the work specification in the SOS_Task::Param, and the WorkDispatcher within that scheduler is then asked to accept the task for immediate or eventual dispatching. Side note: it looks as if SOS_Scheduler::EnqueueTask() is inlined within EnqueueTaskDirectInternal, so we can imagine it being in the call stack before WorkDispatcher::EnqueueTask().
In simple terms, the network listener derives a resource group and chooses a node, the node chooses a scheduler, and the scheduler delegates the enqueue to its WorkDispatcher component.
Ideally an idle worker will have been found and assigned to the task. If so, that worker is now put on its scheduler’s runnable queue by the network listener thread, taking it out of the WorkDispatcher. If no worker is available, the task is still enqueued, but in the WorkDispatcher’s wallflower list of workerless tasks, giving us our beloved THREADPOOL wait.
Let’s however assume that we have a worker. Over on the other side, its underlying thread is still sleeping, but tied to a worker which is now on its scheduler’s runnable queue. It will eventually be woken up to start its assigned task in the normal course of its scheduler’s context switching operations. And what screenplay was thrown over the wall for it to read?
Here we get an extra level of abstraction. The instantiated task runs the TDS parser, which creates and invokes specialised classes based on the contents of the TDS packet. In this case we got a SQL batch request, so a CSQLSource was instantiated to encapsulate the text of the request and set to work on it, taking us down the road of SQL parsing, compilation, optimisation and execution.
Once parallelism comes into play, such a task could instantiate yet more tasks, but that is a story for another day.
Conclusion
From a high enough view, this is quite elegant and simple. A handful of tasks are created to get SQL Server in motion; some of these have the ability to create other tasks, and the machine just chugs on executing all of them.
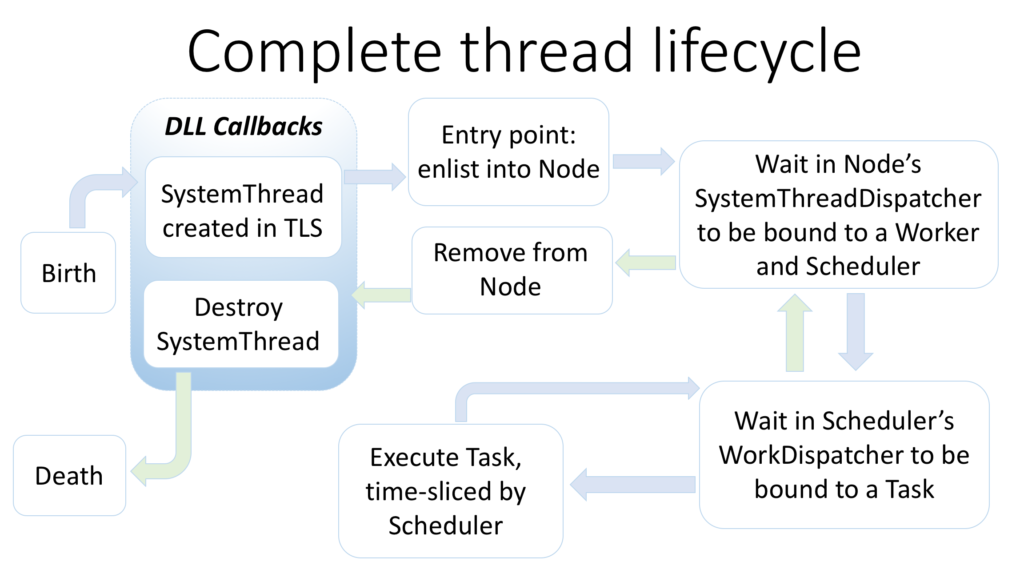
To tie this up with the previous post, here is the complete lifecycle of a SQLOS thread:
The SQLOS thread lifecycle
If you haven’t lately read Remus Rusanu’s excellent Understanding how SQL Server executes a query, do pay it a visit. This post is intended to complement its opening part, although I’m placing more emphasis on the underlying classes and methods recognisable from stack traces.
Since we’ve now covered the thread lifecycle from birth into its working life, next up I’ll go back and look at what a wait feels like from the worker angle.
As with the droppings of the Questing Beast, we recognise synchronisation code paths by their emissions. But even when not leaving telltale fewmets, these creatures wander among us unseen, unsung, until shutdown doth us part.
Today I’ll be examining the SOS_UnfairMutexPair, the synchronisation object behind memory allocations. While I’m going to describe synchronisation as a standalone subject, it’s useful to think of it as theCMEMTHREAD wait; to the best of my knowledge nothing other than memory allocations currently uses this class.
For context, I have previously described a bunch of other synchronisation classes:
The EventInternal, which underpins all cooperative waiting. Note that this has been reborn as WaitableBase in SQL Server 2017.
Latches, which may not be part of SQLOS, but have influenced SQLOS synchronisation. The Latch Files: Out for the count is a good intro to the rich use of atomic compare-and-set operations we’ll see in simplified form today.
One picture which emerges from all these synchronisation flavours is that a developer can choose between busy waiting (eagerly burning CPU), politely going to sleep (thread rescheduling), or a blend between the two. As we’ll see the SOS_UnfairMutexPair goes for a peculiar combination, which was clearly tuned to work with the grain of SQLOS scheduling.
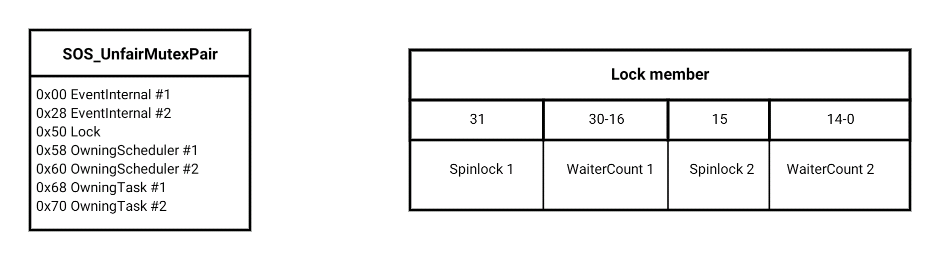
The shape of the object
With the exception of the central atomic lock member, everything comes in pairs here. The class models a pair of waitable objects, each having an associated pair of members to note which scheduler and task currently owns it:
Layout of the SOS_UnfairMutexPair (2016 incarnation)
Although it exposes semantics to acquire either both mutexes or just the second, in its memory allocation guise we always grab the pair, and it effectively acts as a single mutex. I’ll therefore restrict my description by only describing half of the pair.
Acquisition: broad outline
The focal point of the mutex’s state – in fact one might say the mutex itself – is the single Spinlock bit within the 32-bit lock member. Anybody who finds it zero, and manages to set it to one atomically, becomes the owner.
Additionally, if you express an interest in acquiring the lock, you need to increment the WaiterCount, whether or not you managed to achieve ownership at the first try. Finally, to release the lock, atomically set the spinlock to zero and decrement the WaiterCount; if the resultant WaiterCount is nonzero, wake up all waiters.
Now one hallmark of a light-footed synchronisation object is that it is very cheap to acquire in the non-contended case, and this class checks that box. If not owned, taking ownership (the method SOS_UnfairMutexPair::AcquirePair()) requires just a handful of instructions, and no looping. The synchronisation doesn’t get in the way until it is needed.
However, if the lock is currently owned, we enter a more complicated world within the SOS_UnfairMutexPair::LongWait() method. This broadly gives us a four-step loop:
If the lock isn’t taken at this moment we re-check it, grab it, simultaneously increment WaiterCount, then exit triumphantly, holding aloft the prize.
Fall back on only incrementing WaiterCount for now, if this is the first time around the loop and the increment has therefore not been done yet.
Now wait on the EventInternal, i.e. yield the thread to the scheduler.
Upon being woken up by the outgoing owner releasing the lock as described above, try again to acquire the lock. Repeat the whole loop.
The unfairness derives from the fact that there is no “first come, first served” rule, in other words the wait list isn’t a queue. This is not a very British class at all, but as we’ll see, there is a system within the chaos.
The finicky detail
Before giving up and waiting on the event, there is a bit of aggressive spinning on the spinlock. As is standard with spinlocks, spinning burns CPU on the optimistic premise that it wouldn’t have to do it for long, so it’s worth a go. However, the number of spin iterations is limited. Here is a slight simplification of the algorithm:
If the scheduler owning the lock is the ambient scheduler, restrict to a single spin.
Else, give it a thousand tries before sleeping.
Each spin involves first trying to grab both the lock and (if not yet done) incrementing WaiterCount. If that doesn’t work, just try and increment the WaiterCount.
This being of course the bit where the class knows a thing or two about SQLOS scheduling: If I am currently running, then no other worker on my scheduler can be running. But if another worker on my scheduler currently holds the lock, it can’t possibly wake up and progress towards releasing it unless *I* go to sleep. Mind you, this is already a edge case, because we’d hope that the owner of this kind of lock wouldn’t go to sleep holding it.
To see how scheduling awareness comes into play, I’m going to walk through a scenario involving contention on such a mutex. If some of the scheduling detail makes you frown, you may want to read Scheduler stories: The myth of the waiter list.
A chronicle of contention
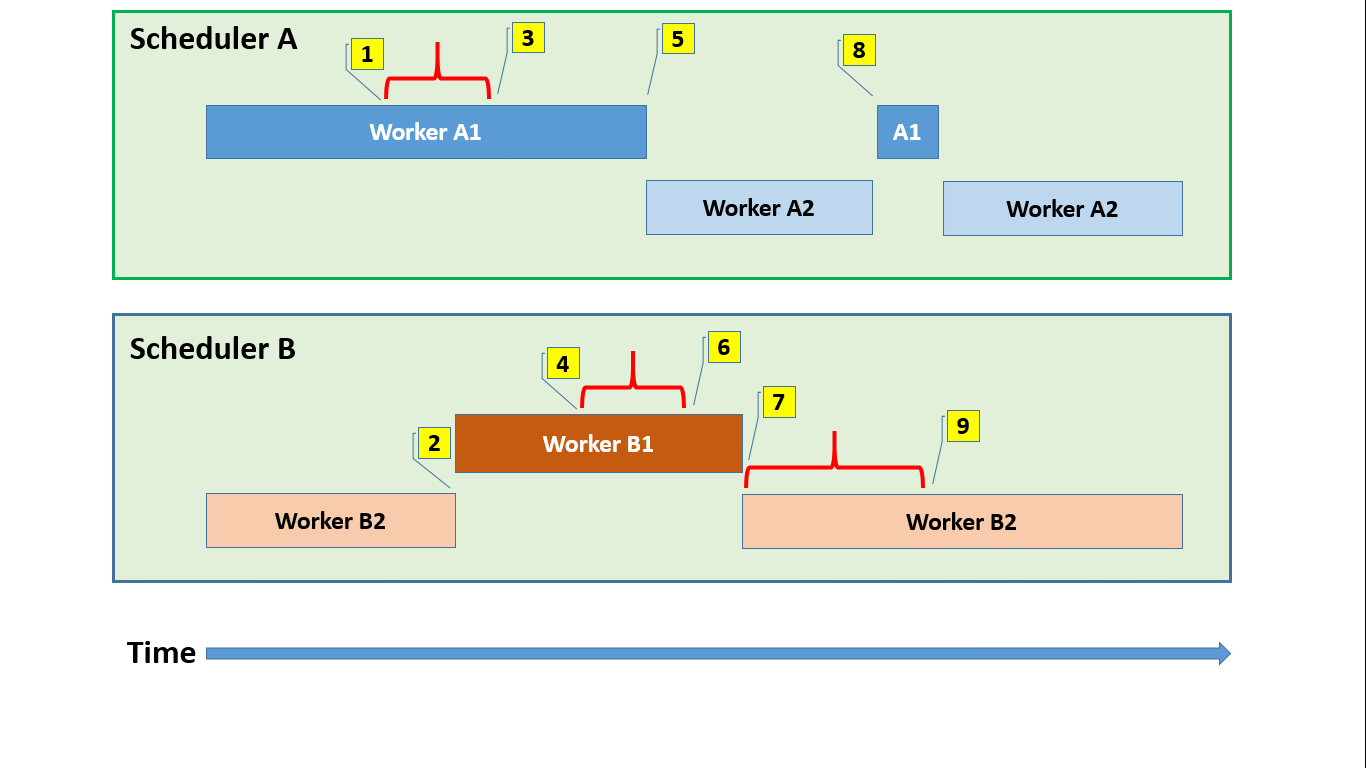
In this toy scenario, we have two schedulers with two active workers each. Three of the four workers will at some point during their execution try and acquire the same mutex, and one of them will try twice. Time flows from left to right, and the numbered callouts are narrated below. A red horizontal bracket represents the period where a worker owns the mutex, which may be a while after the acquisition attempt started.
The mutex acquisition tango
A1 wants to acquire the mutex and, finding it uncontended, gets it straight away.
B2 tries to acquire it, but since it is held by A1, it gives up after a bit of optimistic spinning, going to sleep. This gives B1 a turn on the scheduler.
A1 releases the mutex, and finding that there is a waiter, signals it. This moves B2 off the mutex’s waiter list and onto scheduler B’s runnable queue, so it will be considered eligible for running at the next scheduler yield point.
B1 wants the mutex, and since it isn’t taken, grabs it. Even though B2 has been waiting for a while, it wasn’t running, and it’s just tough luck that B1 gets it first.
A1 wants the mutex again, but now B1 is holding it, so A1 goes to sleep, yielding to A2.
B1 releases the mutex and signals the waiter A1 – note that B2 isn’t waiting on the resource anymore, but is just in a signal wait.
B1 reaches the end of its quantum and politely yields the scheduler. B2 is picked as the next worker to run, and upon waking, the first thing it does is to try and grab that mutex. It succeeds.
A2 reaches a yield point, and now A1 can get scheduled, starting its quantum by trying to acquire the mutex. However, B2 is still holding it, and after some angry spinning, A2 is forced to go to sleep again, yielding to A1.
B2 releases the mutex and signals the waiting A1, who will hopefully have better luck acquiring it when it wakes up again.
While this may come across as a bit complex, remember that an acquisition attempt (whether immediately successful or not) may also involve spinning on the lock bit. And this spinning manifests as “useful” work which doesn’t show up in spinlock statistics; the only thing that gets exposed is the CMEMTHREAD waiting between the moment a worker gives up and goes to sleep and the moment it is woken up. This may be followed by another bout of unsuccessful and unmeasured spinning.
All in all though, you can see that this unfair acquisition pattern keeps the protected object busy doling out its resource: in this case, an memory object providing blocks of memory. In an alternative universe, the mutex class may well have decided on its next owner at the moment that the previous owner releases it. However, this means that the allocator won’t do useful work until the chosen worker has woken up; in the meantime, the unlucky ones on less busy schedulers may have missed an opportunity to get woken up and do a successful acquire/release cycle. So while the behaviour may look unfair from the viewpoint of the longest waiter, it can turn out better for overall system throughput.
Of course, partitioning memory objects reduced the possibility of even having contention. But the fact remains: while any resources whatsoever are shared, we need to consider how they behave in contended scenarios.
Compare-and-swap trivia
Assuming we want the whole pair, as these memory allocations do, there are four atomic operations performed against the lock member:
Increment the waiter count: add 0x00010001
Increment the waiter count and grab the locks: add 0x80018001
Just grab the locks (after the waiter count was previously incremented): add 0x80008000
Release the locks and decrement the waiter count: deduct 0x80018001
For the first three, the usual multi-step pattern comes into play:
Retrieve the current value of the lock member
Add the desired value to it, or abandon the operation, e.g. if we find the lock bit set and we’re not planning to spin
Perform the atomic compare-and-swap (lock cmpxchg instruction) to replace the current value with the new one as long as the current value has not changed since the retrieval in step 1
Repeat if not successful
The release is simpler, since we know that the lock bits are set (we own it!) and there is no conditional logic. Here the operation is simple interlocked arithmetic, but two’s complement messes with your mind a bit: the arithmetic operation is the addition of 0x7ffe7fff. Not a typo: that fourth digit is an “e”!
This all comes down to thinking of the lock bit as a sign bit we need to overflow in order to set to 1. The higher one overflows out of the 32-bit space, but the lower one overflows into the lowest bit of the first count. To demonstrate, we expect 0x80018001 to turn to zero after applying this operation:
8001 8001
+ 7ffe 7fff
---------
(1) 0000 0000
Final thoughts
So you thought we’ve reached the end of scheduling and bit twiddling? This may turn out to be a perfect opportunity to revisit waits, and to start exploring those memory objects themselves.
I’d like to thank Brian Gianforcaro (b | t) for feedback in helping me confirm some observations.
It’s SQLbits this week, and I’m as excited as a query going through the compile semaphore for the first time, so I’m taking a break from the heavy stuff and gossiping about bugs instead.
The thing about linked lists
I’ve previously done a blog post on doubly linked lists, but here is all you really need to know:
A list entry consists of two pointers, flink (forward link) and blink (backward link).
This structure is embedded at a known offset within the object that wants to be within the list. Because the offset is known, no extra pointer is required to point to the containing object.
The list head is also a flink/blink pair, living within the object that owns the list. An empty list is denoted by both flink and blink pointing to the list head iself.
Because list manipulation needs multiple updates, it can’t be done atomically, and inevitably the list is protected by a spinlock. Even reading it safely requires acquiring the spinlock first, and this is one of the reasons why singly linked lists feature in Hekaton.
Traversing a list involves getting the address of the next entry – flink or blink, depending on direction- and then doing something with the containing record. This may be as simple as checking an attribute and returning that object if it is the desired item, or continuing the traversal if it is not.
On the implementation detail side, you’ll normally find that a function to retrieve a list entry will return a null pointer, i.e. the value zero, when it finds an empty list, because it can’t validly return the address of the list head itself. Consuming code will then treat the null pointer as a signal value that nothing was found, and it will most certainly not try and dereference that value by treating it as an address.
Examples from the wild
These beasties are sometimes easy to recognise from a data dump alone. Here is what the list head for an empty list looks like, in this case from the very CBatch instance I was looking at while researching last week’s post:
Two pointer-sized members, the first one pointing to itself, and the second also pointing to the first, or strictly speaking to the pair starting with the first.
Then we have a list with a single entry, which is also easy to recognise by sight: both flink and blink of the list head point to the same list entry, and both flink and blink of that list entry point back to the list head. Interestingly, from those two bits of information alone, it’s impossible to tell which is the list head and which is the list item.
Here is the listhead within a CSession instance pointing at the list item for the single CBatch within that session:
This is a lovely textbook example. Firstly the vftable symbol confirms that we’re dealing with a CBatch, but the list entry starts at offset 8 and not 0. What this means is that one gets at the CBatch instance linked into this particular list by deducting 8 from the list entry’s address.
One way to cause a stack dump
In my previous post, I referenced one of Kendra Little’s Dear SQL DBA episodes, where she demonstrates a stack dump. The exception that led to the stack dump in question was a particular variation on a null reference:
Now I must admit that I didn’t get around to running Kendra’s repro and checking for myself, but this looks like a slam dunk for a dereference problem on a linked list while simultaneously demonstrating a clever safety convention.
Let’s start with the safety convention. The “null” of a null pointer isn’t a magic value, but in real-life implementation is simply zero, which is a perfectly valid virtual address. However, on the premise that trying to access address zero or addresses near it probably indicates a program error, the OS will map that page in such a way that trying to access it causes an access violation. This is not a bug or an accident, but a damn clever feature! Robert Love explains it very nicely over here for Linux, and it applies equally to Windows.
Now recall the convention that trying to retrieve the head or tail of an empty list will – by convention – bring you back a null pointer. When iterating, a related convention may also return a zero when you’ve gone all the way around and come back to the list head. Clearly the onus is on the developer to recognise that null pointer and not dereference it, but attempting to do so sets in motion the safety feature of an access violation, which can then be neatly caught through standard exception handling, for instance yielding a diagnostic stack dump.
Finding a dereference of address zero doesn’t suggest much in itself – zeroes can come from lots of sources. But the address 8 is far more evocative. If you are doing linked list traversal, the normal direction is through blink, which is accessed by adding eight to the address of the list item. And let’s say that you got the value zero as the address of your list item, but didn’t check the value before doing that dereference, you’d be dereferencing address 8. Hey, there can be other ways to get to address 8, but this is a strong candidate.
I should of course emphasise that diagnostic code such as DBCC PAGE jumps through hoops to avoid standard safety features like taking out locks while remaining “safe enough”, so finding a null pointer bug in such an area is just a reinforcement of the idea that this is unsupported, undocumented, and doesn’t necessarily live by the platinum standards expected in the rest of the product.
Lurking bugs that don’t bite
Ah, the thrill of the chase. There is a perverse delight in reading through a bit of disassembly and finding that logical hole where a safety check was only half-done. Here is an example from the beginning of a function (which will remain unnamed) to the point where we have a null-reference bug – I added simple labels and ASCII-art arrows for control flow.
mov rax,qword ptr [rcx+58h]
add rcx,50h
cmp rax,rcx
+------ je *1*
|
| text rax,rax ; is rax == 0?
+------ je *1*
|
| add rax, 0FFFFFFFFFFFFFFF8h ; i.e. subtract 8
| +- jmp *2*
v |
*1* | xor eax,eax ; i.e. mov rax,0
v
*2* cmp dword ptr [rax+1ACh], r8d ; <-- may dereference address 1AC
It's all in the last two instructions. A path exists where rax may contain the value 0, and while you'd normally expect the zero-check before the dereference, that zero-check is missing.
Now unlike the DBCC PAGE example, which has been known to go wrong, this is in a "production" function which doesn't appear to blow up all the time, i.e. the preconditions for the bug coming to light simply aren't there. In practical terms, at the point this function is called, clearly the list in question is never empty. Does that kind of code pattern even count as a bug? I guess the only thing that makes it stand out is the acknowledgement that we may find rax to be zero, or even force it to zero, right before the dereference. But this is probably inherited from an inlined function, and it is only in the disassembly that we see the juxtaposition so clearly.
For my part, I shall continue to delight in finding oddities like this. But at the same time it reminds me that I have a lot to be humble about: if I can spot these little things in the code produced by seriously good programmers, just think of the horrors they would be able to find in my code.
A few weeks ago, Kendra Little did a very entertaining Dear SQL DBA episode about stack dumps. That gave me a light bulb moment when I tied the preamble of her stack dump example to a DBCC command that I’ve had on the back burner for a while. The command puts some session-related objects on stage together, and those objects bridge the gap between a DMV-centric view of the SQL Server execution model and the underlying implementation.
Let’s revisit the purpose of a dump. When you catch one of these happening on your server, it’s sensible to be alarmed, but it is rather negative to say “Oh no, something horrible went wrong!” A more positive angle is that a disturbance was detected, BUT the authorities arrived within milliseconds, pumped the whole building full of Halon gas, and then took detailed forensic notes. Pity if innocent folks were harmed by that response, but there was cause to presume the involvement of a bad hombre, and that is the way we roll around here.
Today we’ll be learning lessons from those forensic notes.
Meet DBCC TEC
Boring old disclaimer: What I am describing here is undocumented, unsupported, likely to change between versions, and will probably make you go blind. In fact, the depth of detail exposed illustrates one reason why Microsoft would not want to document it: if end users of SQL Server found a way to start relying on this not changing, it would hamstring ongoing SQL Server improvement and refactoring.
With that out of the way, let’s dive right into DBCC TEC, a command which can dump a significant chunk of the object tree supporting a SQL Server session. This result is the same thing that shows up within a dump file, namely the output of the CSession::Dump() function – it’s just that you can invoke this through DBCC without taking a dump (cue staring match with Kendra). Until corrected, I shall imagine that TEC stands for Thread Execution Context.
In session 53 on a 2014 instance, I start a batch running the boring old WAITFOR DELAY ’01:00:00′, and while it is running, I use another session to run DBCC TEC against this session 53. The DBCC command requires traceflag 3604, and I’m going to ignore the first and third parameters today; my SQL batch then looks like this:
DBCC TRACEON(3604);
DBCC TEC(0,53,0);
Here is the output I got, reformatted for readability, and with the bulk of the long output buffer omitted:
First observation: this is a treasure trove, or perhaps a garbage dump. Second observation: the output could actually get a lot more verbose, depending on what the session under scrutiny is doing.
All in all, the fact of its inclusion in dump files tells us that it contains useful information to support personnel, and helps to add context in a crash investigation.
A glimpse of the object tree
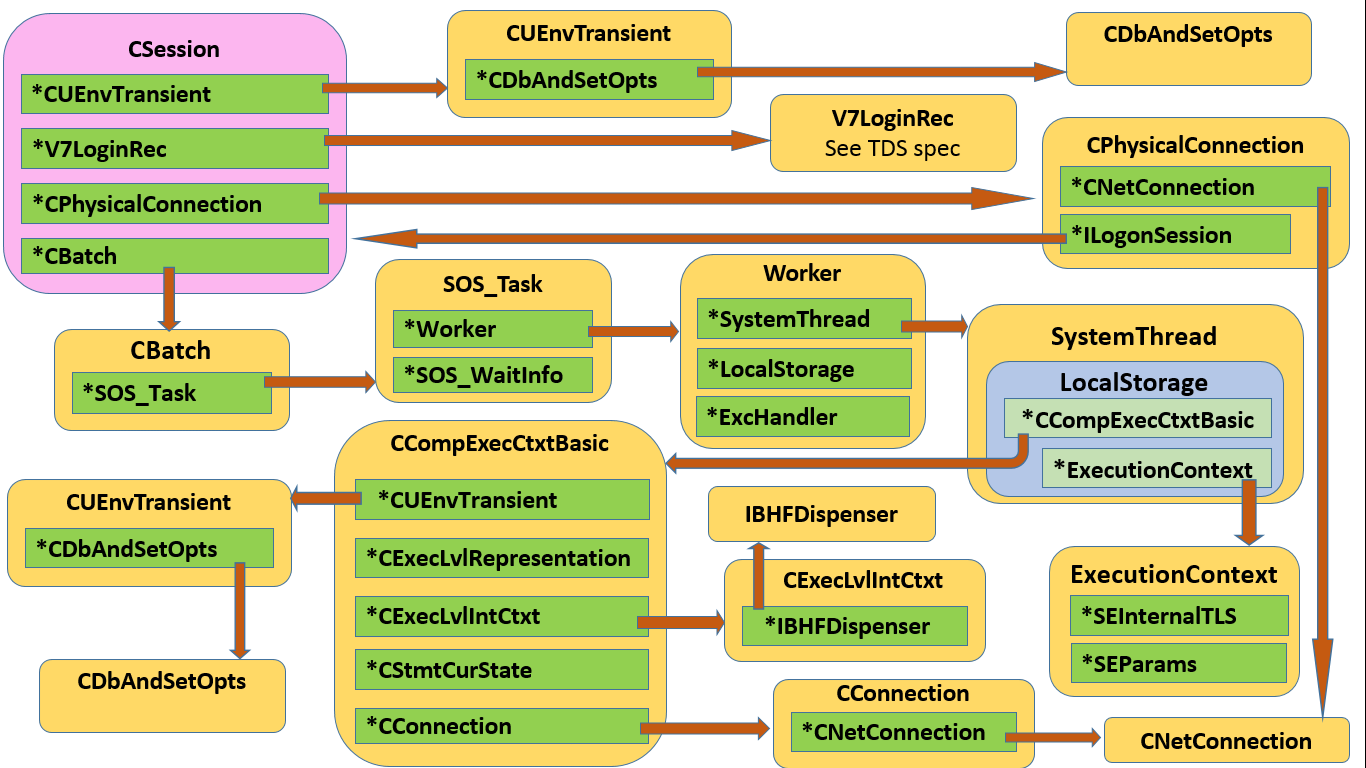
You certainly can’t accuse DBCC TEC of being easy on the eyes. But with a bit of digging (my homework, not yours) it helps to piece together how some classes fit together, tying up tasks, sessions and execution contexts.
Recall that Part 5 demonstrated how one can find the CSession for a given thread. DBCC TEC walks this relationship in the other direction, by deriving tasks and threads – among other things – from sessions.
While this isn’t made obvious in the text dump, below diagram illustrates the classes involved, and their linkages.
The object tree revealed by DBCC TEC
Of course these are very chunky classes, and I’m only including a few members of interest, but you should get the idea.
Observations on DBCC TEC and class relationships
Let’s stick to a few interesting tidbits. CSession is the Big Daddy, and it executes CBatches. Although we’d normally only see a single batch, under MARS there can be more; this manifests by the session actually having a linked list of batches, even though normally the list would contain a single item (I simplified to a scalar on the diagram).
A session keeps state and settings within a CUEnvTransient, which in turn refers to a CDbAndSetOpts. You should recognise many of those attributes from the flattened model we see in DMVs.
However, to make it more interesting, a task (indirectly) has its own CUenvTransient; this is one reflection on the difference between batch-scoped and session-scoped state. And on top of that, even a session actually has two of them, with the ability to revert to a saved copy.
Although a CBatch may execute CStatements, we don’t see this here. The actual work done by a batch is of course expressed as a SOS_Task, which is a generic SQLOS object with no knowledge of SQL Server.
At this point the DBCC output layout is a bit misleading. Where we see EXCEPT (null) it is SOS_Task state being dumped, and we’re not within the CBatch anymore. However, the SOS_Task is actually just the public interface that SQLOS presents to SQL Server, and some of the state it presents live in the associated Worker. The exception information lives within an ExcHandler pointed to by the Worker, and things like CPU Ticks used come directly from the Worker. Task State is the same rather convoluted derivation exposed in sys.dm_os_tasks, as outlined in Worker, Task, Request and Session state. ThreadID is an attribute of the SystemThread pointed to by the task’s Worker, and similarly SchedulerID comes indirectly via the Task’s SOS_Scheduler.
WAITINFO_INTERNAL and (where applicable) WAITINFO_EXTERNAL describe cooperative and preemptive waits respectively. The latter can actually get nested, giving us a little stack of waits, as described in Going Preemptive.
Now we start peering deeper into the task, or rather through it into its associated worker’s LocalStorage as described in Part 5. The first two slots, respectively pointing to a CCompExecCtxtBasic and an ExecutionContext, have their contents dumped at this point.
The ExecutionContext points to one instance each of SEInternalTLS and SEParams. Pause here for a moment while I mess with your mind: should the task in question be executing a DBCC command, for instance DBCC TEC, the m_pDbccContext within the SEInternalTLS will be pointing to a structure that gives DBCC its own sense of context.
Another fun observation: while SEInternalTLS claims with a straight face to have an m_owningTask member, I call bull on that one. Probably it did in the past, and some poor developer was required to keep exposing something semi-meaningful, but the address reported is the address of the ambient task, i.e. the one running DBCC TEC. The idea of ownership is simply not modelled in the class.
Then (still down in the LocalStorage of a Task performed by the Batch under scrutiny) we get the CCompExecCtxtBasic we saw in Part 5. This now shows us a few more members, starting with a CConnection which in turn points to a CNetConnection getting its buffers dumped for out viewing pleasure. This CConnection is in fact the same one pointed to directly by the Batch as m_pConn.
Now, as already mentioned, we see the CUEnvTransient with associated CDbAndSetOpts belonging to the task at hand (through its Worker’s LocalStorage->CCompExecCtxtBasic).
The next CCompExecCtxtBasic member is a pointer to a CEvevLvlIntCtxt which in turn references an IBHFDispenser; in case you’re wondering, BHF stands for BlobHandleFactory, but I’m not going to spill the beans on that yet, because I am fresh out of beans.
Finally, CCompExecCtxtBasic’s performance ends with the duo of CExecLvlRepresentation and a CStmtCurState, neither of whom has much to say.
Whew. That was the superficial version.
Are we all on the same page?
While we could spend a lot of time on what all these classes really do, that feels like material for multiple separate blog posts. Let’s finish off by looking at the pretty memory layout.
Recall that addresses on an 8k SQLOS page will cover ranges ending in 0000 – 1FFF, 2000 – 3FFF, 4000 – 5FFF etc, and that all addresses within a single such page will have been allocated by the same memory object. Now note that the objects which expose a pmo (pointer to memory object) all point to 0x38772040. This sits on (and manages) a page stretching from 0x38772000 to 0x38773FFF.
Have a look through those object addresses now. Do you see how many of them live on that page? This is a great example of memory locality in action. If a standard library’s heap allocation was used, those addresses would be all over the place. Instead, we see that the memory was allocated, and the objects instantiated, with a clear sense of family membership, even though the objects are notionally independent entities.
As a final note on the subject of memory addresses, the eagle-eyed may have noticed that the CPhysicalConnection has a m_pSess pointer which is close to, but not equal to the address of the CSession at the top of the object tree. This is because it is an ILogonSession interface pointer to this CSession instance, with the interface’s vftable living at an offset of 0x58 within the CSession class. See Part 3 for more background.
Further reading
Go on and re-read Remus Rusanu’s excellent How SQL Server executes a query. If you’ve never read it, do so now – it’s both broad and deep, and you can trust Remus on the details.
While reading it, see in how many places you can replace e.g. “Session” with “CSession”, and you will be that bit closer to Remus’s source code-flavoured subtext.
Time to switch context to an old thread, specifically the SystemThread class. I have done this to death in an Unsung SQLOS post, but if you don’t want to sit through that, here are the bits we care about today:
All work in SQLOS is performed by good old-fashioned operating system threads.
SQLOS notionally extends threads with extra attributes like an associated OS event object, and behaviour like a method for for waiting on that event. This bonus material lives in the SystemThread class, which is conceptually a subclass of an operating system thread, although this isn’t literally class inheritance.
A SystemThread instance lives in memory which is either allocated on the heap and pointed to by a thread-local storage slot, or it squats right across a range of TLS slots within the Thread Environment Block.
Due to the nature of thread-local storage, at any moment any code running on a SQLOS thread can get a reference to the SystemThread it’s running on; this is described in gory detail in Windows, Mirrors and a sense of Self. Powerful stuff, because this ambient SystemThread indirectly exposes EVERYTHING that defines the current SQL Server context, from connection settings to user identity and beyond.
Life is a box of ogres
LS through the looking glass
Understanding SQLOS takes us only so far, because it is after all just the substrate upon which SQL Server is built. We’ve now reached the point where SQLOS hands SQL Server a blank slate and says “knock yourself out”.
This blank slate is a small but delicious slice of local storage: an array of eighteen pointers living within the SystemThread. SQLOS has no interest in what these are used for and what they mean. As far as it is concerned, it’s just a bunch of bytes of no known type. But of course SQL Server cares a lot more.
Park that thought for a moment to consider that we’re starting to build up a hierarchy of thread-local storage:
Upon an OS context switch, the kernel swaps the value held in the CPU’s GS register to point to the Thread Environment Block of the incoming thread.
Within this Thread Environment block lives TLS slots that SQLOS takes advantage of. One of these will always point to the currently running SystemThread instance. In other words, when the kernel does a context switch, the change of OS thread brings with it a change in the ambient SystemThread which can be retrieved from TLS.
Now within this SystemThread, an array of eighteen pointer-sized slots are made available for the client application (SQL Server) to build upon.
What does this mean from the viewpoint of SQL Server? Well, even within the parts that don’t care about SQLOS and the underlying OS, code can express and find current thread-specific state – at a useful abstraction level – somewhere within those eighteen slots.
Worker LocalStorage vs thread-local storage
We often skirt around the distinction between a worker and a thread. This is a benign simplification, because instances of Worker and SystemThread classes are bound together in a 1:1 paired relationship during all times when SQL Server code is running.
The only time the distinction becomes particularly interesting is when we’re in fiber mode, because now a single SystemThread can promiscuously service multiple Workers in a round-robin fashion. I have documented some details in The Joy of Fiber Mode, but of special interest today is the treatment of these local storage slots.
These now become a more volatile part of thread context, and a SQLOS context switch (in this case, a fiber switch) must include copying the Worker’s LocalStorage payload into the SystemThread slots, because there is no guarantee that two different Workers will share the exact same context; in fact it is close to certain they won’t.
So clearly the context that matters to the Task at hand lives within the Worker, and SQLOS makes sure that this is the context loaded into a SystemThread while it runs; it’s just that the SQLOS scheduler has to intervene more in fiber mode, whereas it can let this bit of state freewheel in thread mode.
On to the implementation details then. Unlike the case with the SystemThread, a Worker’s local storage isn’t a chunk of memory within the class, but lives in a heap allocation, represented by an instance of the LocalStorage class embedded within the Worker.
Additionally, while the SystemThread’s slot count is baked into SQLOS, somebody clearly wanted a bit more abstraction in the Worker class, so the slot count becomes an attribute of a LocalStorage instance, which thus consists of a grand total of two members:
The slot count, passed into the LocalStorage constructor
A pointer to the actual chunk of memory living somewhere on the heap and allocated by the LocalStorage constructor, which is a thin wrapper around a standard page allocator
Show me some numbers, and don’t spare the horses
On to the fun bit, but you’re going to have to take my word on two things. Firstly, the SystemThread’s local storage slots are right at the start of the object. And secondly, the LocalStorage instance lives at an offset of 0x30 within a Worker, at least on the version I’m using here.
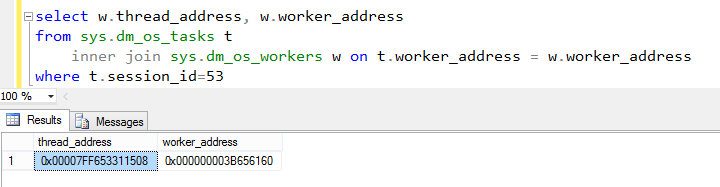
To prepare, I needed to capture the addresses of a bound SystemThread:Worker pair before breaking into the debugger, so I started a request running in session 53, executing nothing but a long WAITFOR – this should keep things static enough while I fumble around running a DMV query in another session:
Capturing the worker and thread addresses of our dummy request
So we’re off yet again to stage a break-in within Windbg. Having done this, everything is frozen in time, and I can poke around to my heart’s content while the business users wonder what just happened to their server. No seriously, you don’t want to do this on an instance that anyone else needs at the same time.
Here is the dump of the first 64 bytes of that Worker. As in Part 4, I’m dumping in pointer format, although only some of these entries are pointers or even necessarily 64 bits wide. In case it isn’t clear, the first column is the address we’re looking at, and the second column is the contents found at that address. The dps command sweetens the deal a bit: if that payload is an address corresponding to a known symbol (e.g. a the name of a function), that symbol will be displayed in a third column.
Those highlighted last two represent the LocalStorage instance, confirming that we do indeed have eighteen (=0x12) slots, and telling us the address where that slot array starts. Let’s see what payload we find there:
It seems that only five out of the eighteen are in use. Oh well, that’s neither here nor there. Let’s compare this to the first eighteen quadwords at the bound SystemThread’s address we found in sys.dm_os_threads:
This isn’t the same address as the Worker’s local storage array, but the contents is the same, which is consistent with my expectation. I’m highlighting that first entry, because we’ll be visiting it later.
Just out of interest, I’m also going to try and tie things back to memory page observations made in Part 4. Let’s peek at the top of the 8k page that the LocalStorage lives on. Its address is 0x3b656c80, which rounded down to the nearest 8k (=0x2000) gives us a page starting address of 0x3b656000.
The shape of that page header looks familiar. The second quadword is a pointer to the address 0x40 bytes into this very page. And just to hand it to us on a plate, the object starting there reveals itself by its vftable symbol to be a CMemObj.
In other words, this particular bit of LocalStorage is managed by a memory object which lives on its very page – obviously it would be wasteful if a memory object refused to share its page with some of the objects it allocated memory for. Also note that this is a plain CMemObj and not a CMemThread<CMemObj>, i.e. it isn’t natively thread-safe. This may simply confirm that local storage is not intended for sharing across threads; see Dorr for more.
Cutting to the chase
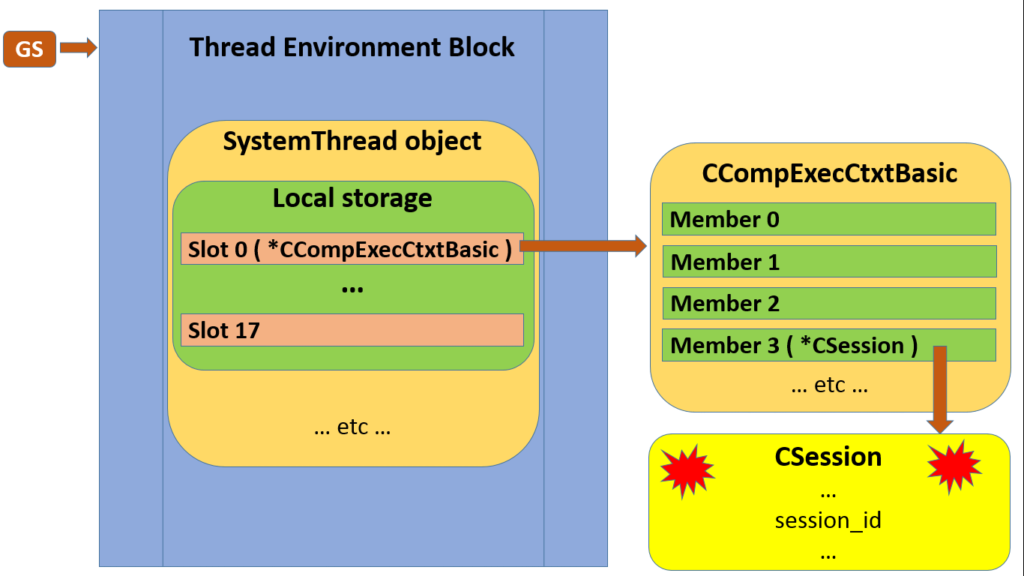
So far, this is all rather abstract, and we’re just seeing numbers which may or may not be pointers, pointing to heaven knows what. Let me finish off by illuminating one trail to something we can relate to.
Out of the five local storage slots which contain something, the first one here points to 00000000`3b656040. As it turns out, this is an instance of the CCompExecCtxtBasic class, and you’ll just have to take my word for it today. Anyway, we’re hunting it for its meat, rather than for its name. Have some:
You may recognise by the range of memory addresses we’ve seen so far that most of these are likely themselves pointers. I’ll now lead you by the hand to the highlighted fourth member of CCompExecCtxtBasic, and demonstrate what that member points to:
Bam! Given away by the vftable yet again – this is a CSession instance, in other words probably the session object associated with that running thread. As per Part 3, the presence of more than one vftable indicates that we may be dealing with multiple virtual inheritance in the CSession class.
We’ll leave the last word for the highlighted third line, containing the value 0x35 as payload.
What does 0x35 translate to in decimal? Would you believe it, it’s 53, the session_id of the session associated with the thread. If we were feeling bored, we could go and edit it to be another number, essentially tinkering with the identity of that session. But today is not that day.
Putting it all together in a diagram, here then is one trail by which an arbitrary chunk of SQL Server code can find the current session, given nothing more than the contents of the GS register:
Sure, your programming language and framework may very well abstract away this kind of thing. But that doesn’t mean you aren’t relying on it all the time.
Final thoughts
This exercise would qualify as a classic case of spelunking, where we have a general sense of what we’d expect to find, perhaps egged on by a few clues. Just as I’m writing this, I see that Niels Berglund has also been writing about spelunking in Windbg. So many angles, so much interesting stuff to uncover!
The key takeaway should be a reminder of how much one can do with thread-local storage, which forms the third and often forgotten member of this trio of places to put state:
Globally accessible heap storage – this covers objects which are accessible everywhere in a process, including ones where lexical scope attempts to keep them private.
Function parameters and local variables – these have limited lifespans and live in registers or on the stack, but remain private to an invocation of a function unless explicitly shared.
Thread-local storage – this appears global in scope, but is restricted to a single thread, and each thread gets its own version of the “same” global object. This is a great place to squirrel away the kind of state we’d associate with a session, assuming we leverage a link between sessions and threads.
I hope that the theme of this series is starting to come together now. One or two more to go, and the next one will cover sessions and their ancillary context in a lot more breadth.
Although today’s post is loosely related to the esoterica of multiple virtual inheritance I unearthed in part 3, it is far more straightforward and goes no further than single inheritance. Spoiler alert: people come up with clever stuff.
Part 3 was a riff on the theme of finding the address of an object, given the address of an interface (vftable) within that object. This was made possible by a combination of member offsets known at compile time and offsets explicitly stored within the object. Now we move on to discover how the address of one object can be derived from the address of another, purely by convention and without relying on magic numbers known only to the compiler or stored in runtime structures. Sounds interesting?
I have often walked down this deck before
But the water always stayed beneath my neck before
It’s the first time I’ve had to scuba dive
When I’m down on the deck where you live.
Come dive with me
In Part 2, the last example was a function which optionally called commondelete as object disposal after the class destructor:
sqllang!CSecContextToken::`vector deleting destructor':
=======================================================
mov qword ptr [rsp+8],rbx
push rdi
sub rsp,20h
mov ebx,edx
mov rdi,rcx
call sqllang!CSecContextToken::~CSecContextToken
test bl,1
+-+- je LabelX
| |
| | { if low bit of original edx was set
| -> mov rcx,rdi
| call sqllang!commondelete
| }
|
LabelX:
+--> mov rax,rdi
mov rbx,qword ptr [rsp+30h]
add rsp,20h
pop rdi
ret
So what does commondelete() do? Well, quite simply it is a global function that releases a previously allocated block of memory starting at the supplied address. Prior to the construction of an object, we need to allocate a chunk of memory to store it in, and after its destruction, this memory must be given back to the pool of available memory. Forgetting to do the latter leads to memory leaks, not to mention getting grounded for a week.
Notionally we can imagine a global portfolio of active memory allocations, each chunk uniquely identified by its starting address. When we want memory, we ask the global memory manager to lend us some from the unused pool, and when we’re done with it, we hand it back to that memory manager, who carefully locks its internal structures during such operations, because we should only access mutable global state in a single-threaded manner, and…. Oops. No, no, double no. That is not how SQL Server does things, right?
Okay, we know that there are actually a variety of memory allocators out there. If nothing else, this avoid the single bottleneck problem. But now the question becomes one of knowing which allocator to return a chunk of memory to after we’re done with it.
One possible solution would be for the object which constructs a child object to store its own reference to the allocator, and this parent object is then the only object who is allowed to destroy its child object. However, this yields a system where all objects have to exist in a strict parent-child hierarchy, which is very restrictive.
As it turns out, many interesting SQL Server objects control their lifetime through reference counting. If object A wants to interact with object B, it first announces that interest, which increases the reference count on B. This serves as a signal that B can’t be disposed, i.e. the pointer held by A remains valid. Once done, A releases the reference to B, which decreases B’s reference count again. Ultimately, B can only be destroyed after its reference count has reached zero. One upshot of this is that objects can live independent lives, without forever being tied to the apron strings of a parent object.
From that given, the problem becomes this: an object playing in this ecosystem must carry around a reference to its memory allocator. Doing it explicitly is conceptually simple. However, it would be onerous, because this pointer would take up an eight-byte chunk of memory within the object itself, which can be a significant tax when you have a large number of small objects. Perhaps more significantly, it raises the complexity bar to playing along, because now all objects must be born with a perfectly-developed plan for their own eventual death, and they must implement standardised semantics for postmortem disposal of their bodies. That’s harsh, not to mention bug-prone.
Far better then would be a way for an outside agent to look at an object and know exactly where to press the Recycle button, although the location of that button is neither global nor stored within the target object.
Pleasant little kingdom
Imagine a perfectly rational urban design; American grid layout taken to the extreme. Say you live at #1137 Main Street and want to find the nearest dentist, dentistry being of particular importance in this kingdom. Well, the rule is simple: every house number divisible by 100 contains a dentist, and to find your local one you just replace the last two digits of your house number with zeros.
That is the relationship that objects have with their memory allocators under SQLOS, except that we are dealing with 8192-byte pages. Take the address of any object in memory, round that address down to the next lower page boundary, and you will find a page header that leads you directly or indirectly to the memory object (allocator) that owns the object’s memory; this object will happily receive the notification that it can put your chunk of memory back into the bank.
I’m skipping some detail around conditionals and an indirect path, but the below is the guts of how commondelete() takes an address and crafts a call to the owning memory object to deallocate that target object and recycle the corpse:
mov rdx, rcx
and rcx, 0FFFFFFFFFFFFE000h
; now rdx contain the address we want to free
; and rcx is the start of the containing page
mov rcx, qword ptr [rcx+8]
; now rcx contains the 2nd qword on the page.
; This is the address of the memory object,
; aka pmo (pointer to memory object)
mov rax, qword ptr [rcx]
; 1st qword of object = pointer to vftable
; Now rax points to the vftable
call qword ptr [rax+28h]
; vftable is an array of (8-byte) function
; pointers. This calls the 6th one. Param 1
; (rcx) is the pmo. Param 2 (rdx) is the
; address we want to free.
See, assembler isn’t really that bad once you put comments in.
Show me
Let’s find ourselves some SQLOS objects. SOS_Schedulers are sitting ducks, because you can easily find their addresses from a DMV query, and they don’t suddenly fly away. And of course I have explored them before. Below from a sad little VM:
I’m getting scheduled in the morning
Got myself a few candidate addresses, so it’s time to break into song the debugger. I’m going to dump a section of memory in 8-byte chunks, and to make it more interesting, I’ll do so with the dps command, which assumes all the memory contents are pointers, and will call out any that it recognises from public symbols. Never mind that this regimented 8-byte view may be at odds with the underlying data’s shape – it’s just a convenient way to slice it.
Because I know where I’m heading, I’m rounding the starting address down to the start of that 8Kb page:
Firstly, we have a beautiful piece of confirmation that the object starting at 0040 is indeed a scheduler, because its very first quadword contains a pointer to the ThreadScheduler vftable. But we knew that already 🙂
What I’d like to know is what the second quadword on the page, at 0008, is pointing to. Interesting, its address also ends in 0040…
Same thing then, let’s dump a bit of that, starting from the top of that page:
Aha! On a freaking platter. The vftable symbol name confirms that the scheduler’s parent memory object is in fact a CMemThread<CMemObj>. Not only that, but if you look at the second slot, it seems that a memory object is its own owner!
But speaking of the vftable, since we’re now familiar with these creatures as simple arrays of function pointers, let’s dump a bit of it. The full thing is rather long; this is just to give you the idea:
Recall that commondelete() calls the sixth entry, located 0x28 bytes from the start. Unsurprisingly, this is the Free() function. And look, the first three tell us that COM is spoken here.
Takeaway
This is not the time to get into the details of how memory objects actually work, but we sure got a nice little glimpse of what SQLOS does with the memory space. Also, the charming side of vftables was laid bare.
Although the assembler view might look daunting, we saw how a virtual method, in this case Free(), is called, using nothing more than the address of the vftable and the knowledge that the object residing there is (or is derived from) the base type exposing that method.
But let’s not lose sight of the “Context in perspective” goal. Here the context is the address of a single object, and the perspective is seeing it framed by convention within a memory page. By its placement in memory, the object gains the all-important implicit attribute of an owning memory object.
This is the third part of a series about various places where “context” in some form or another crops up within SQL Server. The story so far:
What the CPU sees in you takes us down to a very low level, below such towering abstractions as object instances and threads. Not a prerequisite to make sense of today’s post.
A pretty stack frame is like a melody looks at the stack frame of a single invocation of a single function as a self-contained context within a string of other such contexts up the call chain. Although I’ll pick up examples I first brought up there, again you don’t need to have absorbed it to follow this one.
In this episode, I look at one aspect of polymorphic behaviour, whereby the address we use to refer to an object may change depending on what interface the called member function belongs to.
Come, walk with me
Today the world was just an address, a place for me to live in
In Part 2 my first and simplest example of a member function was the below. For a supplied security context token address in the rcx register, this returns the 32-bit “impersonation type”, which is a member variable, presumably of an enumeration type:
sqllang!CSecContextToken::GetImpersonationType:
===============================================
mov eax,dword ptr [rcx+1188h]
ret
The emphasis back then was on the implicit stack context – while only the ret(urn) instruction explicitly references the stack, the function was written for an ecosystem where one can rely on certain stack conventions being followed.
Now I’ll look at it from another angle: how sure am I that it is indeed the CSecContextToken instance’s address that goes into that first rcx parameter? As a reminder, when calling a class instance method in an object-oriented language, the first parameter is a pointer to the instance, i.e. the address of the block of memory storing its state. However, high-level languages normally hide this parameter from you. What the programmer might think of as the method’s first parameter is actually the second, with the compiler inserting a This pointer as a preceding parameter. This is nothing more than syntactic sugar, e.g. translating the equivalent of the “parameterless” function call h = orderDate.HourPart() into a call of the form h = HourPart(&orderDate). In fact, in .Net, extension method syntax exposes the true nature of “instance” methods.
In a simple class, assuming that rcx is indeed the address of the instance would be a safe guess, but this isn’t a simple class.
Try this pair of GetData() overloads for size. Both take a single address as a parameter, and return a different address; being overloads, I’ll include the function addresses to disambiguate them. Firstly this one which returns an address 0x1448 bytes lower than the supplied address:
sqllang!CSecContextToken::GetData (00007ffb`ee810e40):
======================================================
lea rax, [rcx-1448h]
ret
Clearly if rcx is the This pointer, the return value is something that lives before the CSecContextToken in memory. But the function is within the CSecContextToken class, so that doesn’t look very plausible. We’ll have to assume that rcx doesn’t in fact contain the address of the CSecContextToken instance: that address is somewhere on the West side of rcx. (Spoiler alert. The returned address is actually the address of the CSecContextToken.)
Now for the second overload which calls the first as a tail call after a sleight-of-hand adjustment to rcx:
For the supplied address, take the 32-bit value four bytes below it and sign-extend it to 64 bits. The use of movsxd rather than the zero-extend sibling movzxd tells us that this is a signed member variable, whether or not negative numbers will actually get used in practice.
Deduct this number from the supplied address.
Call the other overload with this adjusted rcx as its first parameter.
Since one calls the other, clearly the two overloads return the same value from the same object instance, but they do so from different starting point addresses:
The first one deals with an rcx that is a fixed offset of 0x1448 bytes away from the address within the object it must return. This return value may be the address of the CSecContextToken, or it may itself be somewhere within it – there isn’t enough information supplied to be certain.
The second one is a lot more complex. Its rcx parameter points somewhere within a structure which itself contains the offset from the address we need to pass to the first overload. In other words, while the first overload’s offset is known at compile time, the second one requires runtime information saved within the object instance to do that little calculation.
The nitty gritty of multiple inheritance
The broad explanation for all these different ways of accessing the same CSecContextToken is that it implements quite a number of interfaces due to multiple inheritance – seven of them to be precise – and each of them has its own virtual function table. I have previously looked at vftables in Indirection indigestion, virtual function calls and SQLOS, but now we have a more chunky context to chew on.
Let’s just back up that assertion by checking our public symbols in Windbg: x /n sqllang!CSecContextToken::`vftable’ yields the following:
It turns out that it’s the last one which is of interest to us, because it is the only one which contains an entry for one of our GetData() method, namely the second one. Here is the evidence: dps 7ffb`effd7ee0:
The first and simpler GetData() overload doesn’t show up in a vftable, but the second does. Oddly, the vftable for the second one lives at an offset of +0x1448 into the class instance – you’re going to have to trust me on this one. So the rcx passed into either variation will actually be the same one! But if the virtual version is called, it needs to find its position relative to +0x1448 dynamically, by doing a data lookup. We can confirm that by peeking at what is saved four bytes earlier at +0x1444, and that is indeed the value zero.
The setup of both vftables and dynamic offset lookups is done within the class constructor, with reference to other structures with the symbol of sqllang!CSecContextToken::`vbtable’. This seems to be the glue keeping compile-time and run-time structures in sync, with each vbtable containing the offsets needed to allow one vftable (interface) to reference another, in other words to be cast to it.
When it comes to virtual multiple inheritance and the implementation of multiple interfaces, the previously solid “this” pointer passed into member functions changes its colours. Either it adapts itself with a known compile-time offset or it does so by doing a runtime lookup.
To make an example of the vftable of the second case:
Clearly a CSecContextToken can be upcast to a CSecCtxtCacheEntry<CSecContextTokenKeySid,1,CPartitionedRefManager>: the vftable tells us it is one of its base types.
However, the act of casting actually adjusts the “this” pointer passed to the function – in this case by adding 0x1448 to it. Then the implementation of that function does further adjustments as needed so it can act upon the intended underlying object rather than on the interface itself.
Inheritance isn’t always this complicated. For single inheritance, even with virtual functions, an object still retains a single vftable, conventionally located at offset zero (in class constructors, you can see these progressively overwriting each other, revealing the hierarchy). But once multiple inheritance and multiple interfaces are involved, each one wants its own vftable, and the fun of static and dynamic address adjustment starts.
There’s a place for us
Long breath. I am not a C++ programmer, and my only prior exposure to multiple inheritance has been of the form “some languages make this possible, but it might fry your brain”. The implementation details sure are frying mine.
Then again, this is another illustration of the kind of thing high level languages do for us. If you can just focus on the right level of abstraction and trust the compiler to get the details right, you are riding a powerful beast. In a handful of cases, the benefit of the abstraction might be outweighed by the performance cost of moving too far from the metal (branch misprediction and memory stalls due to virtual function calls and the interposition of those “this”-adjusting functions), but most code of most people don’t live on that edge.
So without knowing where I was heading, I think SQL Server just taught me a few things about multiple inheritance and the context implications of coding with it. And it seems that those functions that do nothing more than adjust the incoming “this” pointer before delegating to an overload are in fact adjustor thunks. I read about them ages ago, but it went over my head, leaving only the catchy name, but Googling it now seems to make sense.
There is a moral in there. Somewhere. To find your place in the world, sometimes you just have to find your adjustor thunk.
Further reading
Inside the C++ object model by Stanley Lippman covers this kind of ground while staying in C++-rooted explanations. By the nature of the beast, I have been discovering Microsoft-specific implementation details, but now I feel ready to continue working my way through Lippman.
This is part 2 in a series exploring ways in which a chunk of running SQL Server code gains context, i.e. the mechanisms by which a bunch of instructions get to participate in something bigger and just possibly a bit unpredictable. You can find part 1 here. (Update: and now there is also part 3.)
Today’s instalment on the use of the stack may come across as rather obvious or perhaps “computer science-y”, so I’m going to try and sweeten the deal by using small but perfectly nuggets of complete SQL Server functions to illustrate some detail. Detail there will be aplenty, so feel free to skim-read just to get the aroma – that is probably what I would have done if I were in your aromatic shoes. Special thanks to Klaus Aschenbrenner (b1 | b2 | t) for recently filling in a bothersome gap in my knowledge by pointing me to this great resource.
Stacks revisited
Refresher time. In its strict sense, a stack is a LIFO data structure where all interaction occurs through push (insert item at the end) or pop (remove item from that same end) operations. By its nature, a stack grows and shrinks all the time while in use, and it can’t get internally fragmented by having chunks of unused space.
When we talk about “the stack” in Windows, we normally mean the user-mode stack of a specific thread. As functions call each other, the last thing done before transferring control to the callee is to push the address of the next instruction (the return address) on to the stack. Once the callee is finished, the act of returning involves popping that address into the instruction pointer, which transfers control back to the expected point within the caller. Note that this implies a strict requirement for symmetric management of the stack within each function: one push or pop too many, and the control flows goes haywire.
Additionally, the thread stack provides a convenient place to store local variables, within reasonable memory usage limits. The natural flow of stack allocation and cleanup is a perfect fit for variables whose lexical scope and lifetime are restricted to the function invocation.
Every invocation of a function gets its own stack frame. In its most rudimentary form, it consists of only the return address, but it can get arbitrarily big (within reason) as space is allocated for saved registers and local variables. Generally speaking, a function should only work with stack memory within its own stack frame, i.e. on its side of that return address, and anything beyond that has the smell of malicious interference. Special exceptions exist for access to stack-passed parameters and (in the Windows x64 convention) to the shadow space described later. Additionally, a pointer passed from a parent function to a child for an output parameter may very well refer to stack-allocated memory within the parent, and the child can end up legally writing into the stack frame of the parent – after all, as long as it follows good hygiene and doesn’t play buffer overrun games, it shouldn’t care where an output parameter points to.
Traditionally, stacks grow downward in memory, i.e. they start at a high address, with a push operation decrementing the stack pointer, and a pop incrementing it. I tend to visualise high memory addresses as being near the top of a printed page. However, when representing a call chain, standard current usage puts the high memory at the bottom of the page, i.e. the stack grows visually upward.
Whatever language you program in, chances are your compiler does the honours of sorting out the details and not letting you shoot yourself in the foot by corrupting the stack. So this isn’t something where you are normally exposed to the mechanics, unless you look at it from the low-level perspective of assembler code emitted by the compiler.
Calling conventions: the 32-bit vs 64-bit divide
Before getting into details of mechanism, I should point out that stack usage is an area where 64-bit Windows code looks entirely different from 32-bit equivalents. A lot of excellent older resources are 32-bit specific, but I restrict myself to the 64-bit world here.
Specifically, the 32-bit world had quite a number of competing calling conventions, notably cdecl, stdcall, and fastcall. 64-bit Windows specifies a single Application Binary Interface (ABI) based on the old fastcall. This favours parameter passing through registers and thus gets away with much less stack usage, which is a performance bonus, since register accesses are a lot faster than memory access, even disregarding cache misses. Be that as it may, it still makes sense to remember the central position of the stack in function calls.
Leaving aside floating point and SIMD registers, the convention is fairly simple:
Parameter 1 goes in the rcx register
Parameter 2 goes in rdx
Parameter 3 goes in r8
Parameter 4 goes in r9
Further parameters are pushed onto the stack from right to left (standard C convention, which allows for variable number of parameters since the first one will be in a known place)
The function’s return value goes in rax
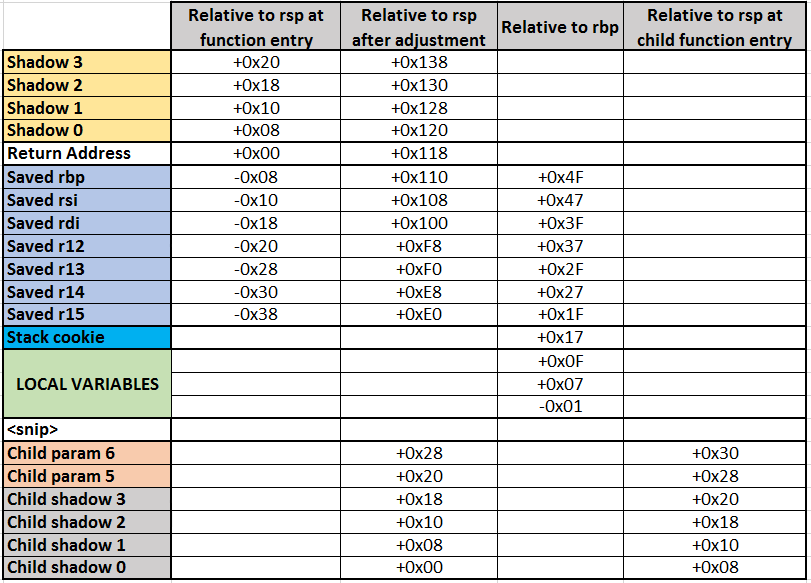
Additionally, the caller of a function must leave 32 bytes free for the callee’s use, located just before (above) the return address. All functions get this scratchpad – known variously as “shadow space” or “parameter homing space” – for free, but only functions which call child functions need to worry about doing this little allocation. Think of it as a memory nest egg.
Finally, while 32-bit code had the freedom to push and pop to their hearts’ content, such adjustment of the stack pointer is now only allowed in a function’s prologue and epilogue, i.e. the very first and very last bit of the emitted code. This is because of another very important convention change. In the 32-bit world, a function always saved the initial value of the stack pointer in the EBP register after pushing the old value of EBP, and this allowed for traversal of the call chain. Such traversal is needed for structured exception handling, as well as for diagnostic call chain dumps, such as the ones we sometimes get exposed to in SQL Server.
However, the mechanism for finding one’s way in the call stack now relies on metadata in the 64-bit world: if something goes wrong while the instruction pointer is at address 0x12345, it is possible for exception dispatching code to know what function we’re in from linker/loader metadata alone. This then allows an appropriate Catch block within the function to be called. And if the exception is uncaught and needs to bubble up? Well, since the stack allocation size of the function is part of that metadata, and the stack pointer doesn’t change during the function body, we can just add a constant to the current stack pointer to find the return address, hence deduce who the caller was, continuing the same game.
Note that all this describes a set of Windows conventions. However, this is still at a level where SQL Server on Linux plays by the Windows rules, up to a certain point within SQLPAL.
A word on Assembler examples
I picked four short SQL Server functions, in gently increasing level of complexity, to illustrate stack frames, finished with the prologue of a bigger function. When you dump functions in Windbg using the uf command, e.g. uf sqllang!CSecContextToken::GetImpersonationAttr, the output includes addresses as loaded, the hexadecimal representation of the instructions, and the human-readable Assembler, for instance:
To remove irrelevant noise, I have stripped my examples down to just the bare Assembler, removing address references except in one place where I substituted the target of a conditional jump with a simple symbol.
Then, to address the elephant in the room: Assembler is verbose but simple. There are only a handful of instructions that do most of the heavy lifting here:
mov dest, source is a simple assignment. Mentally read as “SET @dest = @source”. Square brackets around either operand indicates that we’re addressing a memory location, with the operand designating its address.
lea (load effective address) is essentially a more flexible version of mov, although the square brackets are deceptive: it never accesses memory.
push decrements the stack points (rsp) and then writes the operand at the memory location pointed to by the modified rsp.
pop copies the value at the memory location pointed to by rsp into the operand, and then increments rsp.
add operand, value and sub operand, value respectively adds or subtracts the supplied value from the operand.
jmp is an unconditional jump, loading the instruction pointer with the supplied address (note that symbols are just surrogates for addresses). je (jump if equal/zero) is one of a family of conditional jumps.
call does the same as jmp, except that the jump is preceded by first pushing the address of the next instruction (after the call) onto the stack.
Don’t sweat the details, I’ll explain as we go along.
Example 1: no stack manipulation in function
Here we have a function that looks like a straightforward property accessor. It takes one parameter in rcx, which the caller populated, and it is a reasonable assumption that it will be the “This” pointer for a class instance. Certainly it is a pointer to a memory address, because we dereference the (32-bit) doubleword that is 0x1188 bytes away to come up with a return value.
sqllang!CSecContextToken::GetImpersonationType:
===============================================
mov eax,dword ptr [rcx+1188h]
ret
So what does the stack frame look like? Well, by definition the function call gave us the 32-byte shadow space, although we don’t end up using it, and this is followed by the return address. Within this function, nothing uses the stack except the act of returning.
Nice and simple. From the viewpoint of the rsp value, the bit of the stack we are allowed to take an interest in looks like this:
rsp + 0x20 – shadow space
rsp + 0x18 – shadow space
rsp + 0x10 – shadow space
rsp + 0x8 – shadow space
rsp – return address
How things got set up to be this way isn’t any concern of this function.
Example 2: child function as tail call
The next example features a child call to the standard C library memcpy function. However, since this is the very last thing the function does, we see a so-called tail call optimisation: there is no need to call this function for the sake of it returning to nothing more than a ret instruction. By directly jmping to it, we get the same functionality with fewer instructions and fewer memory accesses, and since we’re done with the shadow space, the child can inherit ours. The return address seen by memcpy() isn’t its caller, but its caller’s caller, and that is all fine and dandy.
This stack frame has the same structure as the previous example, although more non-stack parameters come into play in the child function call. Let’s explore them for laughs.
memcpy() has a well-documented signature, and we can simply look up the parameter list, all of which fit into the pass-by-register convention:
*destination goes in rcx. The assignment “mov rcx, rdx” tells us that this is in fact the second parameter passed to GetImpersonationAttr() – or the first explictly passed parameter after an implicit *This – so we immediately know that GetImpersonationAttr() takes a parameter of a pointer to the target where something needs to be copied, i.e. an output parameter.
*source goes in rdx, and is supplied as the same 0x1188 offset into *This as the previous function, and now we know that the first four bytes of the impersonation attribute structure is in fact the impersonation type. Whatever that means 🙂
num goes into r8d (the lower 32 bits of r8), so clearly the impersonation attribute structure has a size of 0x38 bytes.
Fun fact about tail call optimisation. Textbook explanations of simple recursive functions often work on the premise that you’ll overflow the stack beyond a certain recursion depth. However, many practical recursive functions, including the hoary old factorial example, can have the recursion optimised away into tail calls. The functional programming folks get all frothy about this stuff.
Example 3: stack parameters and child function
In this function, we come up against the need for local storage, meaning a stack allocation is required. This couldn’t be simpler: just pull down the Venetian blind of the stack pointer and scribble on the newly exposed section. Or more concretely, decrement the stack pointer by the amount you need.
This example also involves more than four incoming parameters, hence some will be passed on the stack. And the nature of the function is that it is really just a wrapper for another function, and must pass those same parameters through the stack for the child function. This then also brings the responsibility or pulling down the stack pointer by an extra 32 bytes to provide shadow space for the child function.
Here goes – I added line breaks around pairs of related assignment instructions.
Let’s get the register usage out of the way first: although four of them are invisible in the code, we can infer their presence through convention:
rcx is adjusted before being passed to the child. Assuming that these are both instance methods, this suggests that the CTokenAccessResultCache instance is 0x12A0 bytes into CSecContextToken.
rdx, r8 and r9 are passed straight through to the child function. We can’t tell from this code whether they use the full 64 bits or perhaps only 32, but this would be made more clear from examining the caller or the child.
rax is used as a scratch variable in indirect memory-to-memory copies – such copies can’t be done in a single CPU instruction. However, assuming the child function has a return value, it will be emitted in rax, and that will go straight back to our caller, i.e. the parent inherits the child’s return value.
No other general-purpose registers are touched, so we don’t need to save them.
Boring arithmetic time. What happens here is that seven parameters beyond the four passed in variables get copied from the caller’s stack frame to the child parameter area of our stack frame. The parent saved them at its rsp + 0x20 upwards; with the interposition of the return address, it is our rsp + 0x28 upwards, and then after adjusting rsp by 0x68 it becomes rsp + 0x90 upwards. We dutifully copy them to our rsp + 0x20 upwards, which the child function will again see as rsp + 0x28 upwards.
One interesting sight to call out is the rcx adjustment squeezed in between the “from” and “to” halves of the first parameter copy. This is not messy code, but a classic tiny compiler optimisation. Because two consecutive memory accesses lead to memory stalls, the compiler will attempt to weave non-memory-accessing instructions among these memory access if possible. Essentially we get that addition for free, because it can run during a clock cycle when the memory instruction is still stalling, even in cases where the literal expression of the source code logic suggests a different execution order.
A more interesting observation is that all this allocation and copying is just busywork. For whatever reason, the compiler didn’t or couldn’t apply a tail call optimisation here. If it did, the child function could just have inherited the parent’s parameters, apart from the rcx adjustment, yielding this three-liner:
sqllang!CSecContextToken::FGetAccessResult:
===========================================
add rcx,12A0h
jmp sqllang!CTokenAccessResultCache::FGetAccessResult
ret
Example 4: two child functions and saved registers
This doesn’t add much complexity to the previous one, and is a more straightforward read, although it introduces a conditional branch for fun. Hopefully my ASCII art makes it clear that control flow after the je (jump if equal, or in this case the synonym jump if zero), can either continue or skip the second child function call.
sqllang!CSecContextToken::`vector deleting destructor':
=======================================================
mov qword ptr [rsp+8],rbx
push rdi
sub rsp,20h
mov ebx,edx
mov rdi,rcx
call sqllang!CSecContextToken::~CSecContextToken
test bl,1
+-+- je LabelX
| |
| | { if low bit of original edx was set
| -> mov rcx,rdi
| call sqllang!commondelete
| }
|
LabelX:
+--> mov rax,rdi
mov rbx,qword ptr [rsp+30h]
add rsp,20h
pop rdi
ret
The rdi register is used as a scratchpad to save the incoming rcx value for later – first it is used to restore the possibly clobered rcx value for the second child function call, and then it becomes the return value going into rax. However, since we don’t want to clobber its value for our caller, we first save its old value and then, at the very end, restore it. This is done through a traditional push/pop pair, which in x64 is only allowed in the function prologue and epilogue.
Similarly, ebx (the bottom half of rbx) is used to save the incoming value of the second parameter in edx. However, here we don’t use a push/pop pair, but instead save it in a slot in the shadow space. Why two different mechanisms for two different registers? Sorry, that’s one for the compiler writers to answer.
Example 5: The Full Monty
This example is from a much meatier function – somewhere north of 200 lines – so I’m just going to present the prologue and the very beginning of the function proper. For the sake of readability, I’m again adding a few line breaks around related chunks of instructions.
This has a lot more going on, so to save our collective sanity I have prepared a table of stack offsets relative to rsp at function entry, rbp, and the adjusted rsp. Note that the Local Variables section covers a lot of real estate, but I only listed the first few slots. This picture should drive home the notion of why we talk about a stack “frame”: it is a chunk of memory serving as the frame for a single invocation of a function, as is itself the feaming context for subservient sections.
The MkShowplanRow stack frame
For unknown reasons, rbp comes into play here. This is odd, because its value relative to rsp is constant, and all rbp-relative memory references could have been expressed just as easily by making them rsp-relative. Even more mysteriously, the compiler decides that an unaligned (non divisible by 8) offset is just the ticket. Having said that, it doesn’t change anything from a functional viewpoint; it just means that the arithmetic looks more weird.
I’m not going to do this one line by line, because you can translate things fairly easily using the table as a crutch. If I leave you with the general feeling that those translated angry bracket numbers can be coaxed into something sensible, I have achieved a lot.
So let’s just wrap up with a few highlights:
The local variable at [rbp-19h] receives what appears to be a very large number. Or if you consider it signed (see here for more signed integer gossip), it’s just the value -2. The presence of this variable is is very common in the SQL Server code base, and presumably is part of some convention.
The value of rbx is again saved in the shadow area, while the parameter-carrying registers r9 and rdx get saved lower down in the stack among the rest of the local variables. rcx gets backed up in a register of its own (r13), and rdx goes to r15 in addition to that stack backup. Why both? Again, a compiler quirk.
The value written to [rbp 0x17] is a stack cookie, used as a safety mechanism to detect stack corruption. By its nature, it is an unpredictable value, and when its value is re-checked at the end of the function, detected corruption can be dealt with as an exception.
The assignment of a vftable address to a memory location in the local variable area (line 27), followed by a bunch of further zero-value initialisations of subsequent addresses, is a dead giveaway that we’re constructing a temporary instance of a class with virtual functions, in this case a CShowplanString.
Conclusion and further reading
Gosh, that sure was more detail than I was expecting. And welcome to the end of the post.
I’ll let Gustavo Duarte have the last word again. Thrice.
Journey to the stack is an excellent coverage of the stack in general. Just be aware that it is 32-bit focused.
Waitress: Hello, I’m Diana, I’m your waitress for tonight… Where are you from? Mr and Mrs Hendy: We’re from Room 259. Mr Hendy: Where are you from? Waitress: [pointing to kitchen] Oh I’m from the doors over there…
(Monty Python, “The Meaning of Life”)
When code runs, there is always an implied context. Depending on what level of abstraction you’re thinking at, there are endless angles from which to consider the canvas upon which we paint executing code.
Some examples, roughly in increasing level of abstraction:
What machine is it running on, and what is the global hardware setup for things like memory size and cache configuration?
Within this machine, what CPU is currently executing the code in question?
Within the currently executing function, what state was passed to it through parameters and global variables, and what would a point-in-time snapshot of the function invocation’s current state look like?
Under what credentials is the current thread executing that function, and what rights are associated with those credentials?
What is the bigger technical task being performed, from what source site was this ultimately invoked, and what application-level credentials are modeled for this task?
What business problem is being solved?
In this short series of blog posts, I’m going to cherry-pick a few technical subjects in this line of thinking, conveniently sticking with ones where I actually have something to contribute, because that way the page won’t be blank. And this will of course happen in the (ahem) context of SQL Server.
What is the point-in-time context of a running CPU?
The x64 Intel CPUs we know and love have a state which can broadly be defined as the current values of a set of user-visible registers, each of which is nothing more than a global variable that is only visible to that CPU. Ignoring floating-point and SIMD ones, this leaves us with a handful:
RIP, the instruction pointer, which points to the address of the current instruction (Thanks Klaus for finding an embarrassing typo there!). Normally we only interact with this through its natural incrementing behaviour, or by causing it to leap around through jump/call instructions (planned control flow) or a hardware interrupt (out-of-band interventions).
RSP, the stack pointer. This is also automatically managed through stepwise changes as we do stack-based operations, but we can and do interact with it directly at times.
RAX, RBX, RCX, RDX, RSI, RSI, RBP, and R8 through R15 – these are general-purpose registers that can be used however we like. Some of them have associations with specific instructions, e.g. RDI and RSI for memory copying, but they remain available for general-purpose use. However, beyond that, strong conventions keep their use sane and predictable. See Register Usage on MSDN for a sense of how Windows defines such conventions.
The segment registers CS, DS, ES, FS, GS and SS. These allow a second level of abstraction for memory address translation, although in modern usage we have flat address spaces, and they can mostly be ignored. The big exception here is GS, which both Windows and Linux uses to point to CPU- or thread-local structures, a usage which is explicitly supported by Intel’s SWAPGS instruction. However, I’m getting ahead of myself here, because this occurs at a much higher level of abstraction.
Context switching in its most basic form involves nothing more than saving a snapshot of these registers and swapping in other values saved previously. Broadly speaking, this is what the Windows CONTEXT structure is all about. By its nature, this is processor architecture-specific.
One interesting thing comes up when you consider how tricky it is to talk about the point-in-time state of a pipelined CPU, since it could be executing multiple instructions at the same time. The answer here is one that will have a familiar ring to database folks: although the incoming stream of instructions is expressed linearly, that clever CPU not only knows how to parallelise sections of them, but it can treat such groups as notionally transactional. In database-friendly terms, only the right stuff commits, even in the face of speculative execution.
This end up as a battle of wits between the CPU and compiler designers. Any suffienctly clever optimising compiler will reorder instructions in a way which lubricates the axles of instruction-level parallelism, and any sufficiently clever CPU will internally reorder things anyway, irrespective of what the compiler emitted. But fortunately for our sanity, we can still think of the CPU’s PacMan-like progress through those delicious instructions as happening in a single serial stream.
A CPU asks “Who am I?”
It shouldn’t come as a surprise that a single CPU has precious little awareness of its surroundings. In reading and writing memory, it may experience stalls caused by contention with other CPUs, but it has no means – or indeed need – to get philosophical about it.
Our first stopping point is a dive into the very simple Windows API call GetCurrentProcessorNumber(). This does pretty much what it says, but its workings highlights how this isn’t a hardware or firmware intrinsic, but instead something cooked up by the operating system.
Before we get to the implementation, consider how even such a simple thing can twist your brain a bit:
Who is asking the question? Candidate answer: “The thread, executing the code containing the question on the processor which has to answer it.”
Because threads can be switched between processors, the answer may cease to be correct the moment it is received. In fact, it can even become incorrect within GetCurrentProcessorNumber(), before it returns with the wrong answer.
So here in all its three-line glory, is the disassembly of the function from my Windows 8.1 system:
mov eax, 53h
lsl eax, eax
shr eax, 0Eh
ret
This uses the unusual incantation lsl (load segment limit), which dereferences and decodes an entry in the Global Descriptor Table, returning a segment limit for entry 0x53, itself a magic number that is subject to change between Windows versions. Compared to normal assembly code, this is esoteric stuff – for our purposes we we only need to know that the Windows kernel puts a different value in here for each processor as it sets it up during the boot process. And it abuses the segment limit bit field by repurposing it, smuggling both the processor number and the kernel group number into it: the processor number is the higher-order chunk here. (If this kind of thing makes your toes curl in a good way, you can actually see the setup being done in systembg.asm in the Windows Research Kernel. Some Googling required.)
This sets the tone for this exploration of context. At any given level, we find that something at a lower level stuffed nuggets of information in a safe – ideally read-only – location for us to read. I should emphasise in this example that even though GetCurrentProcesor is an OS function, it isn’t a system call requiring an expensive kernel transition. If we wrote our own copy of it within our own DLL, it would be rude in terms of breaking abstraction, but it would have just as much of a right to read that GDT entry as the Windows-supplied function does.
Let’s visit the kernel in disguise
It’s unavoidable that we would occasionally need to make a system call, and here we encounter another way identity is turned sideways.
Problem statement: No matter how neatly a system call is wrapped up, it is still just a function taking parameters, and any arbitrary code can invoke any system call. This is a Bad Thing from the viewpoint of enforcing restrictions on who can execute what. How does the kernel know whether it ought fulfil your request to perform a dangerous function if it can’t be sure who you are? Surely it can’t trust your own declaration that you have the authority?
Clearly a trusting kernel is a dead kernel. Here is where we pay another visit to ambient identity. Previously we looked at thread-local storage, where the thread-specific pointer to its user-mode Thread Environment Block is always accessible through the GS register. Now the issue is slightly different: without putting any trust in the content of the TEB, which can be trivially edited by that nasty user-mode code, the kernel needs to have a sense of who is calling into it.
The answer lies yet again in a “secret” storage compartment, in this case one not even exposed to user mode code. Beyond the normal CPU registers I mentioned above, there is a collection of so-called model-specific registers. These are the ones that support lower-level functions like virtual address translation, and even if complete garbage is passed as parameters to a system call, the kernel can find its feet and respond appropriately, e.g. by returning to the caller with a stern error message or even shutting down the offending process entirely.
And here’s the flip side of the coin. In user mode, the locus of identity is a thread, which carries credentials and thread-local storage (for the sake of the user-mode code) and implies a process (for sandbox enforcement by kernel code). In kernel mode though, we cross over into CPU-centric thinking. This is exemplified by what the constant beacon of the GS register gets set to by Windows: in user mode it points to the current thread’s Thread Environment Block, but in kernel mode it changes to point to the current processor’s Processor Control Region, and a similar situation applies in Linux.
Per-processor partitioning of certain thread management functions makes perfect sense, since we’d aim to minimise the amount of global state. Thus each processor would have its own dispatcher state, its own timer list… And hang on, this is familiar territory we know from SQLOS! The only difference is that SQLOS operates on the premise of virtualising a CPU in the form of a Scheduler, whereas the OS kernel deals with physical CPUs, or at least what it honestly believes to be physical CPUs even in the face of CPU virtualisation.
Without even looking at the read-only state passed over to user mode, once a thread calls into the kernel, the kernel can be absolutely sure what that thread is, by virtue of this CPU-centric thinking. “I last scheduled thread 123, and something just called into the kernel from user mode. Ergo, I’m dealing with thread 123.”
We’ll be seeing a few variations on this theme. Whenever thread state (and by extension, session or process state) needs to be protected from corruption, at minimum we need some way of associating a non-overwritable token with that thread, and then saving the state somewhere where the thread can’t get at it except through safe interfaces. For an OS kernel, hardware protection takes care of drawing a line between untrusted code and the kernel. And as we’ll see later, within SQL Server the nature of the interface (T-SQL batch requests) is such that arbitrary code can’t be injected into the application’s process space, and the interface doesn’t allow for uncontrolled privilege escalation.
And all it takes is the ability to squirrel away a single secret.
Gossip hour
In researching this, I came across GetCurrentProcessorNumber() because it is called within a Hekaton synchronisation method that partitions state by CPU. That is itself interesting, since SQLOS tends to encourage partitioning by SQLOS scheduler. A very simple reading would be that this is a symptom of the Hekaton development team having run with the brief to minimise their dependence on existing layers within SQL Server. This is supported by the observation that Hekaton seems to bypass the local storage layer provided within SQLOS workers on top of thread-local storage, directly assigning itself TLS slots from the OS.
In fairness (at least to answer the first point), GetCurrentProcessorNumber() was only added in recent Windows versions, and core SQLOS was developed before that existed. But it is easy to project one’s own experiences of Not Invented Here Syndrome onto others.
So back to “I’m from those doors over there”… In sys.dm_os_threads, we find the column instruction_address, purporting to be the address of the instruction currently executing. Now for a suspended thread, this is a sensible thing to wonder about, but once a thread is running, no outside agent, for instance a DMV-supporting function running on another CPU, has a hope of getting a valid answer. This is documented behaviour for the Windows function GetThreadContext(): “You cannot get a valid context for a running thread”. Then again, any non-running thread will have an instruction address pointing to a SQLOS synchronisation function, which isn’t really interesting in itself without a full stack trace. That leaves the edge case of what value you get for the actual thread which is running sys.dm_os_threads. And the answer is that you get the starting address of sqldk!SOS_OS::GetThreadControlRegisters, the function that wraps GetThreadContext(). Turns out that someone put a special case in there to return that hard-coded magic value, rather than the thread attempting to query itself, which I rather like to think of as an Easter egg. The doors over there indeed.
Part 2 will consist of a look into stack frames. See you there!
Further reading
CPU Rings, Privilege, and Protection by Gustavo Duarte. If you want both technical depth and an easy read, you’d be hard pressed to improve on Gustavo’s extraordinary talent. Inside KiSystemService by shift32. Although it is written from a 32-bit viewpoint, it goes very deeply into the actual system call mechanism, including how trap frames are set up. This Alex Ionescu post giving some more technical insight into the (ab)use of segment selectors. If it makes the rest of us feel any better, here we see the co-author of Windows Internals admitting that he, too, had to look up the LSL instruction.
In many ways, it seems that the more recent SQLOSv2/SQLPAL work is a simple case of continuing with a project that has been organically evolving since the SQL Server 7 User Mode Scheduler, and rooted in classic Stonebraker: just how far can we assume control of core OS functions within an RDBMS process? Continue reading “Indirection indigestion, virtual function calls and SQLOS”