So I’ve been having this ongoing discussion with Lonny Niederstadt (b | t) recently, where he tries to make sense of how CheckDB performs, and I fixate on a possibly irrelevant detail. In other words, he talks over my head, and I talk under his feet. Seems fair to me.
Today is the day to air my funny bits, and with some luck Lonny will continue to take us to interesting places in his own explorations.
Update: Aaaand Lonny has delivered a headful!
The thing about external waits
I’m going to go out on a limb and suggest that none of us are very clear about what external waits are. Code external to SQL Server? External to the CPU? Code that was dropped by aliens?
Previously I dug into preemptive waits in SQLOS, and to be honest, I equated “preemptive” with “external”. For the most part the two go hand in hand after all.
To recap, a preemptive wait isn’t necessarily a wait at all. What happens is that a worker needs to run some code that can’t be trusted to play by cooperative scheduling rules. And rather than put the SQLOS scheduler (and all its sibling workers) at the mercy of that code, the worker detaches itself from the scheduler and cedes control to a sibling runnable worker.
The time period from this moment until the worker returns to cooperative scheduling is labeled as a preemptive wait. During this time, one would hope that the thread did indeed sleep a bit, because it would be directly competing for CPU with its sibling through the mediation of the operating system scheduler. In other words, the time ascribed to a preemptive wait covers an unknown combination of working and sleeping.
In that blog post, I also covered the possibility of external waits getting nested: during the time where we’re executing code but counting each passing tick as external wait A, it is possible to declare another external wait B, and temporarily double count the same slice of time against both. Even more confusingly, we could temporarily dip back into cooperative scheduling while the external “wait” continues.
First, a fundamental premise. A wait type is just a label – a task name someone decided to fill in on a notional time card. Different pieces of code can use the same label for different things, or if we’re lucky, a given wait type is used in one place only, and its presence pinpoints the exact function that was running.
Today I’m only talking about the OLEDB wait as it manifests in CheckDB, although a similar story may pertain elsewhere. In case you didn’t read the title, OLEDB is an external wait type that isn’t preemptive. But what does this mean?
It means that some of what I said about preemptive waits still applies, most significantly the idea that code can actively be running while advertising itself as being in a wait. This can be seen as a slight slant on what the wait type measures: we are using an existing mechanism as a profiling tool that surfaces how much time is spend in a certain chunk of code.
However, in this case the worker doesn’t go preemptive, i.e. it doesn’t yield the scheduler to a sibling while it does the work advertised as a wait.
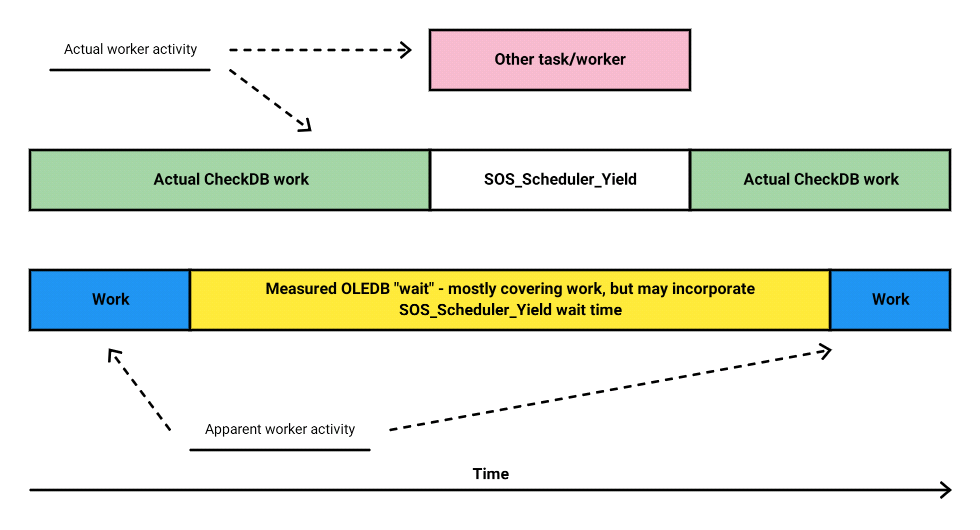
Here it really gets weird. This worker is cooperatively scheduled, and has a conscience that tells it not to hog the scheduler. Every so often, it will offer to yield, and if the scheduler accepts the offer the CheckDB worker will properly go to sleep, with this sleep time labeled as SOS_SCHEDULER_YIELD.
But at the same time, the clock is still ticking on the OLEDB wait!
This is an entirely new twist on double counting. We claim to be waiting, but are working, except that sometimes we do stop working, counting a bit of time against both OLEDB and SOS_SCHEDULER_YIELD.
I am not saying that this happens all the time, but this is the way that a certain branch of code is written, as least in SQL Server 2014. The OLEDB “wait” is declared within CQScanRmtScanNew::GetRowHelper(), and during this “wait” we get a call to CUtRowset::GetNextRows(), which itself calls CTRowsetInstance::FGetNextRow(). However, within GetNextRows(), after every 16 invocations a courtesy call is made to YieldAndCheckForAbort(), which may yield the scheduler with an SOS_SCHEDULER_YIELD wait.
To visualise broadly:
Bonus material: The little preemptive wait that wasn’t
The OLEDB wait is neatly encapsulated in an instance of the CAutoOledbWait class, which in turn contains an SOS_ExternalAutoWait, the same object used by preemptive waits.
Now if we look into SOS_ExternalAutoWait, it comes with three constructors. One gives us a bland UNKNOWN/MISCELLANEOUS wait, presumably on the historic premise that folks didn’t always want to bother categorising their wait activity. Another is fully parameterised, and can emit any supplied wait type. But the third one really catches one’s eye: it’s wired to emit PREEMPTIVE_OS_GETPROCADDRESS.
Clearly PREEMPTIVE_OS_GETPROCADDRESS must serve as a convenient “smoke break” wait type for certain callers, and I’d find it hard to believe that so many people really call GetProcAddress(). So on the premise that nothing in this external wait guarantees it is used preemptively, I am inclined to think that:
- When you see this particular wait, you have to read it as MISCELLANEOUS
- It ain’t necessarily preemptive
See you next time!