
In the last two posts, I gradually climbed up the stack trace of a typical SQLOS thread. Here is such a stack trace from thread creation to context switch, omitting the actual meat of SQL Server so we can focus on the scheduling aspect.
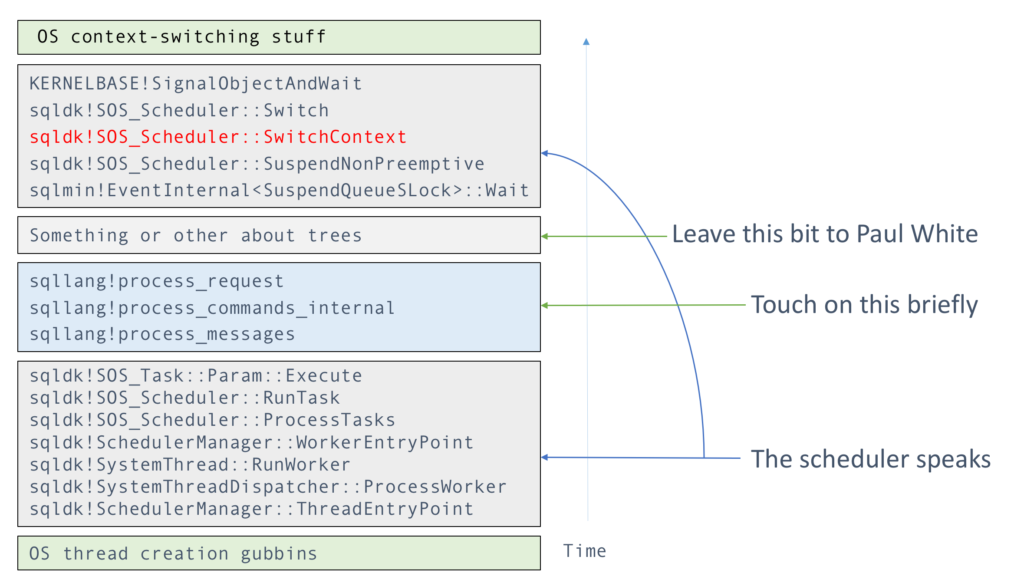
Today I’m looking at the upper part of that map, where the thread was deep in thought, but stepped into the open manhole of a latch wait, which – as is typical for most waits – involves an EventInternal as underlying mechanism.
Slipping into SwitchContext()
The SQLOS scheduler exists in the cracks between user tasks. As we’re well aware, in order for scheduling to happen at all, it is necessary for tasks to run scheduler-friendly code every now and again. In practice this means either calling methods which have the side effect of checking your quantum mileage and yielding if needed, or explicitly yielding yourself when the guilt gets too much.
Now from the viewpoint of the user task, the experience of yielding is no different than the experience of calling any long-running CPU-intensive function: You call a function and it eventually returns. The real difference is that the CPU burned between the call and its return was spent on one or more other threads, while the current thread went lifeless for a bit. But you don’t know that, because you were asleep at the time!
Anyway, for perfectly valid reasons, in the example an EventInternal‘s Wait() method decided to go to sleep, or viewed from a different angle, to put its caller to sleep. We know how that story ends. Ultimately the Wait() call will return, but before then, the thread will snake its way into a cooperative context switch involving SignalObjectAndWait().
The recipe
The EventInternal’s Wait() function is one of a handful of blocking functions that ferry threads into the cooperative context switch – or alternatively you can view it as ferrying the CPU across workers. In SQL Server 2017, you’ll start seeing WaitableBase::Wait(), but this is mostly refactoring, or possibly even un-inlining of existing code phrasing which only now shows up in public symbols.
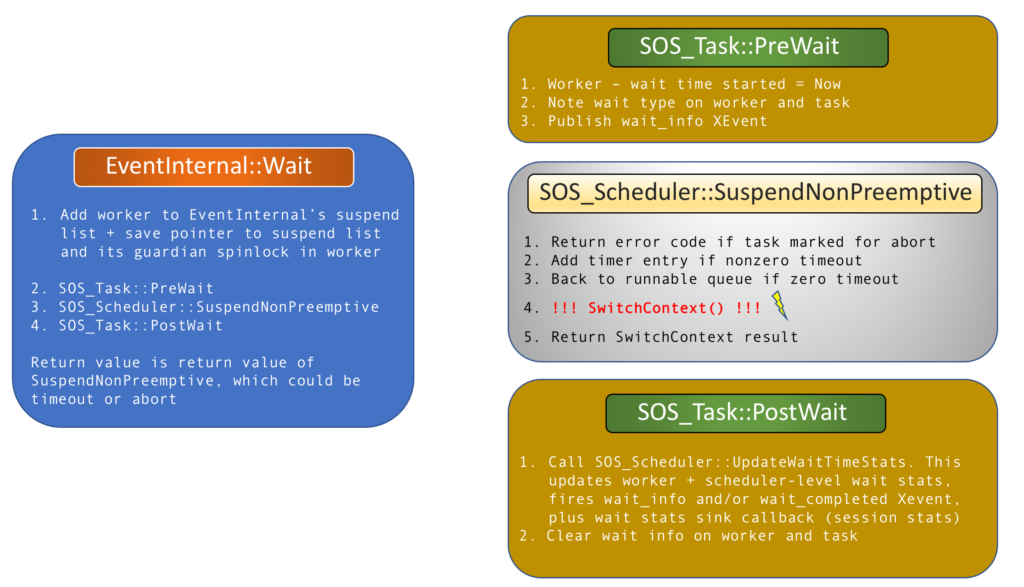
Getting into a context switch and back out again – i.e. eventually having the context switched back to the current thread – in the polite context of a task, includes a sequence of three function calls within Wait():
- SOS_Task::PreWait() – this sets up wait accounting and publishes the wait_info XEvent.
- SOS_Scheduler::SuspendNonPreemptive() – this sets up timeout logic and does a final check for task abort before calling SwitchContext(). The result of SwitchContext (which is ultimately the result of its call to Switch() will be passed back up to Wait() as the wait result.
- SOS_Task::PostWait() – this performs the actual wait accounting and clears the waiting status of the task
These are outlined below:
The elusive SwitchContext() and its uncle Switch()
Okay, I was guilty of a white, or perhaps red, lie by including a call to SwitchContext() in that first diagram. Unless you have a breakpoint on that function, you probably will never see it in a stack trace. This is because it makes a tail call to Switch(), meaning the compiler tranfers control to its child Switch() through a jmp instruction rather than a call, thus erasing and reusing the SwitchContext stack frame. Goto is neither dead nor particularly harmful once you’re into assembly language.
But anyway, there is a nice delineation between the two. Switch() is the lowest-level SQLOS function where a thread may enter and block before eventually returning, and this is where the call to SignalObjectAndWait() happens. As input parameters, it receives a pointer to the current Worker and the one that must be switched to. This includes special handling for the case where the two are the same, e.g. if the worker graciously yielded due to quantum exhaustion, but was the only viable worker on the runnable queue, so got rescheduled immediately. In this case (“InstantResuming” in TaskTransition parlance) there is no mucking about with SignalObjectAndWait, and the function simply returns as soon as it can.
Otherwise, the outgoing worker is tidied up with a TaskTransition call of type “Suspending”, and the long-awaited SignalObjectAndWait ceremony is performed. Next thing it knows, SignalObjectAndWait returns because time passed, other workers ran, and Lady Luck – or if you’re lucky, Father Fairness – chose it as the next worker eligible for a quantum. At this point we get a “Resuming” TaskTransition, and the return value inscribed into the worker by its waker-upper, back when it was put back onto the runnable queue, becomes the return value of Switch() and hence SwitchContext().
However, as a last-ditch guard against against spurious wakeup, should the SignalObjectAndWait call return without the prescribed sacrament of the ambient SystemThread having its LastSignalledBy set by another, we cry foul and go to sleep again using a simple WaitForSingleObject(). As of 2016, there is now even an accompanying premature_systemthread_wakeup XEvent to herald the outrage.
Working backwards then, what does SwitchContext() do? Simple. This is where all the scheduler chores (e.g. checking timer and I/O lists) happen, and crucially, where the next incoming worker is chosen from the runnable queue. Its special case is finding an empty runnable queue, at which point the scheduler’s idle worker is scheduled, which may eventually go to sleep through WaitForSingleObject() on the scheduler’s own idle event. At this point the whole scheduler would be asleep, and it will require another scheduler to wake it up by signalling that idle event.
My, how the runnable queue has grown up. You may have gathered from Bob Dorr’s 2016 updated scheduling algorithms post that the PercentileQueue used in 2012 and 2014 got replaced with something else. What we have in 2016 (and AFAIK in 2017) is the continued use of said PercentileQueue for system schedulers, but the new GroupWorkerQueue for normal ones. This is a thing of beauty, containing a linked list per resource group per scheduler, i.e. partitioned in such a way that little in the way of locking is needed. I would like to highlight that its use doesn’t affect the awarded quantum target, which remains at 4ms, but only which worker gets chosen. One day I might have enough meat to write a whole post about it…
Final thoughts
This touches upon something I scratched at in The Myth of the Waiter List, which can always do with being aired again.
For the most part, a wait list, aka suspend queue, is something that belongs to a synchronisation resource like a latch or a a reader-writer lock. Apart from the timer and I/O lists, and the work dispatcher, suspend queues have nothing to do with schedulers: the synchronisation objects that own those suspend queues will move a worker from them to the relevant scheduler’s runnable queue when its time is up. The scheduler really only cares about the runnable queue, and will not waste tears or time worrying about workers suspended on synchronisation objects.
It should be clear from the context, but I have completely ignored fiber mode today. A fiber switch is a different beast entirely, and you can read more about it in The Joy of Fiber Mode.
Yes, there is some repetition from earlier posts, but I hope that covering the same ground multiple times in different ways works as well for you as it does for me. Any questions or observations? I’m all ears.
One thought on “In the footsteps of a cooperative wait”