In my previous post I discussed the unsung early years of a SQLOS thread. Now it’s all very well knowing that threads extend themselves with SystemThreads, don Worker outfits, and execute SOS_Tasks, but I keep glossing over where tasks come from.
Gloss no more.
SOS_Task::Param – the seed of a work request
This nested struct only shows up by name in one spot on stack traces, when we see the below call as the crossover point between thread setup boilerplate and the meat of the task:
sqldk!SOS_Task::Param::Execute
This is a simple piece of abstraction, calling a previously specified function pointer with a previously specified parameter value. Those two values are the core data members of the SOS_Task::Param. In itself, such a pair is similar to the pair one would pass to a thread creation call like CreateRemoteThreadEx(). However, among the other data members we find SQLOS-specific things like a pointer to a resource group, the XEvent version of task identity and – if applicable – a parent task. These do pad out the picture a bit.
Now the SOS_Task::Param is a comparatively small structure, but it contains the core of what a task is about. Without it, an SOS_Task is a bag of runtime state without a defined mission, and isn’t “executable”. It’s just a typed block of memory: 984 bytes in the case of SQL Server 2016 SP1, of which the Param takes up 68 bytes.
Ultimately, getting a task run translates into this: Specify what you want done by phrasing it as an SOS_Task::Param, and get “someone” to create and enqueue a task based on it to a WorkDispatcher.
Which came first, the task or the task?
I have lately been spending some delightful hours unpicking the SQL Server boot process. For now, let’s stick with the simple observation that some tasks are started as part of booting. One example would be the (or nowadays “a”) logwriter task, whose early call stack looks like this:
sqlmin!SQLServerLogMgr::LogWriter
sqldk!SOS_Task::Param::Execute
sqldk!SOS_Scheduler::RunTask
sqldk!SOS_Scheduler::ProcessTasks
sqldk!SchedulerManager::WorkerEntryPoint
sqldk!SystemThread::RunWorker
sqldk!SystemThreadDispatcher::ProcessWorker
sqldk!SchedulerManager::ThreadEntryPoint
KERNEL32!BaseThreadInitThunk
ntdll!RtlUserThreadStart
Everything up to RunTask() is the thread starting up, getting married to a worker, and dequeuing a task from the WorkDispatcher. Apart from it being enqueued by the boot process, and the task never really completing, there is nothing special about this core piece of system infrastructure. It is just another task, one defined through an SOS_Task::Param with sqlmin!SQLServerLogMgr::LogWriter as its function pointer.
Here is one that is actually a bit more special:
sqldk!SOS_Node::ListenOnIOCompletionPort
sqldk!SOS_Task::Param::Execute
sqldk!SOS_Scheduler::RunTask
sqldk!SOS_Scheduler::ProcessTasks
sqldk!SchedulerManager::WorkerEntryPoint
sqldk!SystemThread::RunWorker
sqldk!SystemThreadDispatcher::ProcessWorker
sqldk!SchedulerManager::ThreadEntryPoint
KERNEL32!BaseThreadInitThunk
ntdll!RtlUserThreadStart
This is of course the network listener that makes it possible for us to talk to SQL Server whatsoever. It is a bit unusual in using preemptive OS scheduling rather than the cooperative SQLOS flavour, but this only affects its waiting behaviour. What makes it very special is that this is the queen bee: it lays the eggs from which other tasks hatch.
The SQL nursery
The above system tasks wear their purpose on their sleeves, because the function pointer in the SOS_Task::Param is, well, to the point. The tasks that run user queries are more abstract, because the I/O completion port listener can’t be bothered with understanding much beyond the rudiments of reading network packets – it certainly can’t be mucking about with fluent TDS skills, SQL parsing and compilation, or permission checks.
So what it does is to enqueue a task that speaks TDS well, pointing it to a bunch of bytes, and sending it on its way. Here is an example of such a dispatch, which shows the “input” side of the WorkDispatcher:
sqldk!WorkDispatcher::EnqueueTask sqldk!SOS_Node::EnqueueTaskDirectInternal sqllang!CNetConnection::EnqueuePacket sqllang!TDSSNIClient::ReadHandler sqllang!SNIReadDone sqldk!SOS_Node::ListenOnIOCompletionPort ...
At this point, the Resource Group classifier function will have been run, and the target SOS_Node will have been chosen. Its EnqueueTaskDirectInternal() method picks a suitable SOS_Scheduler in the node, instantiates an SOS_Task based on the work specification in the SOS_Task::Param, and the WorkDispatcher within that scheduler is then asked to accept the task for immediate or eventual dispatching. Side note: it looks as if SOS_Scheduler::EnqueueTask() is inlined within EnqueueTaskDirectInternal, so we can imagine it being in the call stack before WorkDispatcher::EnqueueTask().
In simple terms, the network listener derives a resource group and chooses a node, the node chooses a scheduler, and the scheduler delegates the enqueue to its WorkDispatcher component.
Ideally an idle worker will have been found and assigned to the task. If so, that worker is now put on its scheduler’s runnable queue by the network listener thread, taking it out of the WorkDispatcher. If no worker is available, the task is still enqueued, but in the WorkDispatcher’s wallflower list of workerless tasks, giving us our beloved THREADPOOL wait.
Let’s however assume that we have a worker. Over on the other side, its underlying thread is still sleeping, but tied to a worker which is now on its scheduler’s runnable queue. It will eventually be woken up to start its assigned task in the normal course of its scheduler’s context switching operations. And what screenplay was thrown over the wall for it to read?
sqllang!CSQLSource::Execute sqllang!process_request sqllang!process_commands_internal sqllang!process_messages sqldk!SOS_Task::Param::Execute ...
Here we get an extra level of abstraction. The instantiated task runs the TDS parser, which creates and invokes specialised classes based on the contents of the TDS packet. In this case we got a SQL batch request, so a CSQLSource was instantiated to encapsulate the text of the request and set to work on it, taking us down the road of SQL parsing, compilation, optimisation and execution.
Once parallelism comes into play, such a task could instantiate yet more tasks, but that is a story for another day.
Conclusion
From a high enough view, this is quite elegant and simple. A handful of tasks are created to get SQL Server in motion; some of these have the ability to create other tasks, and the machine just chugs on executing all of them.
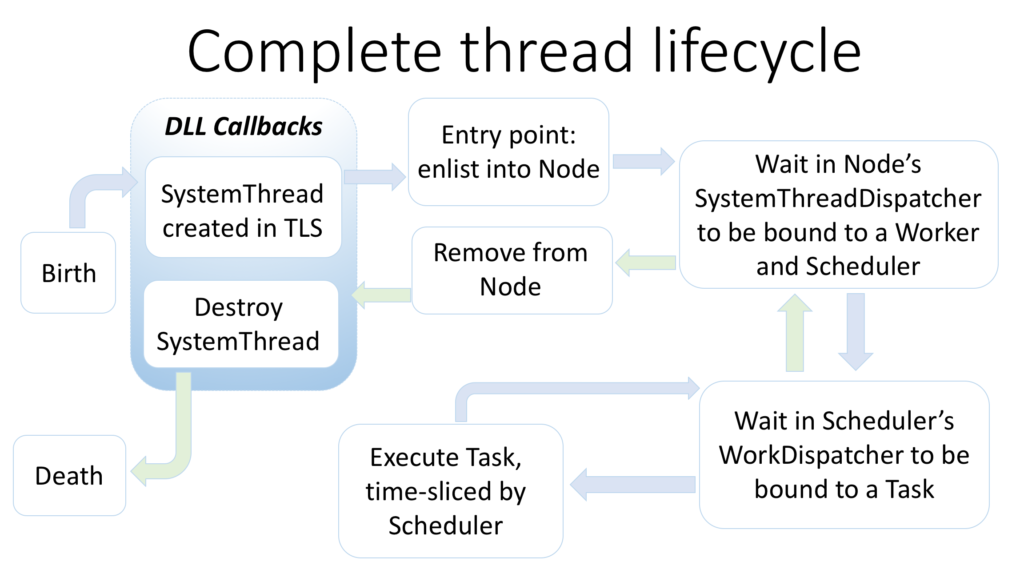
To tie this up with the previous post, here is the complete lifecycle of a SQLOS thread:
If you haven’t lately read Remus Rusanu’s excellent Understanding how SQL Server executes a query, do pay it a visit. This post is intended to complement its opening part, although I’m placing more emphasis on the underlying classes and methods recognisable from stack traces.
Since we’ve now covered the thread lifecycle from birth into its working life, next up I’ll go back and look at what a wait feels like from the worker angle.