A few weeks ago, Kendra Little did a very entertaining Dear SQL DBA episode about stack dumps. That gave me a light bulb moment when I tied the preamble of her stack dump example to a DBCC command that I’ve had on the back burner for a while. The command puts some session-related objects on stage together, and those objects bridge the gap between a DMV-centric view of the SQL Server execution model and the underlying implementation.
Let’s revisit the purpose of a dump. When you catch one of these happening on your server, it’s sensible to be alarmed, but it is rather negative to say “Oh no, something horrible went wrong!” A more positive angle is that a disturbance was detected, BUT the authorities arrived within milliseconds, pumped the whole building full of Halon gas, and then took detailed forensic notes. Pity if innocent folks were harmed by that response, but there was cause to presume the involvement of a bad hombre, and that is the way we roll around here.
Today we’ll be learning lessons from those forensic notes.
Meet DBCC TEC
Boring old disclaimer: What I am describing here is undocumented, unsupported, likely to change between versions, and will probably make you go blind. In fact, the depth of detail exposed illustrates one reason why Microsoft would not want to document it: if end users of SQL Server found a way to start relying on this not changing, it would hamstring ongoing SQL Server improvement and refactoring.
With that out of the way, let’s dive right into DBCC TEC, a command which can dump a significant chunk of the object tree supporting a SQL Server session. This result is the same thing that shows up within a dump file, namely the output of the CSession::Dump() function – it’s just that you can invoke this through DBCC without taking a dump (cue staring match with Kendra). Until corrected, I shall imagine that TEC stands for Thread Execution Context.
In session 53 on a 2014 instance, I start a batch running the boring old WAITFOR DELAY ’01:00:00′, and while it is running, I use another session to run DBCC TEC against this session 53. The DBCC command requires traceflag 3604, and I’m going to ignore the first and third parameters today; my SQL batch then looks like this:
DBCC TRACEON(3604); DBCC TEC(0,53,0);
Here is the output I got, reformatted for readability, and with the bulk of the long output buffer omitted:
TEC: CSession @0x0000000038772470 m_sessionId = 53 m_cRef = 13 m_rgcRefType[0] = 1 m_rgcRefType[1] = 1 m_rgcRefType[2] = 9 m_rgcRefType[3] = 1 m_rgcRefType[4] = 0 m_rgcRefType[5] = 1 m_pmo = 0x0000000038772040 m_pstackBhfPool = 0x0000000000000000 m_dwLoginFlags = 0x100083e0 m_fBackground = 0 m_eConnResetOption = 0 m_fUserProc = 1 m_fConnReset = 0 m_fIsConnReset = 0 m_fInLogin = 0 m_fAuditLoginSent = 1 m_fAuditLoginFailedSent = 0 m_fReplRelease = 0 m_fKill = 0 m_ulLoginStamp = 110 m_eclClient = 7 m_protType = 6 m_hHttpToken = FFFFFFFFFFFFFFFF CUEnvTransient @0x0000000038772A60 m_ululRowcount = 0 m_cidLastOpen = 0 m_lFetchStat = 0 m_lRetStat = 0 m_lLastError = 0 m_lPrevError = 0 m_cNestLevel = 0 m_lHoldRand1 = 0 m_lHoldRand2 = 0 m_cbContextInfo = 0 m_rgbContextInfo = 0000000038772C28 CDbAndSetOpts @0x0000000038772A80 m_fHasDbRef = 0 m_fDateFirstSet = 0 m_fDateFormatSet = 0 m_lUserOpt1 = 0x14817000 m_lUserOpt2 = 0x40 m_lUserOpt1SetMask = 0xfffff7f7 m_idtInsert.objid = 0 m_idtInsert.state = 0 m_idtInsert.dbid = 0 m_llRowcnt = 0 m_lStatList = 0 m_lTextSize = 2147483647 m_lOffsets = 0x0 m_ulLockTimeout = 4294967295 m_ulQueryGov = 0 m_eDtFmt = 1 m_eDayDateFirst = 7 m_eDdLckPri = 0 m_eIsoLvl = 2 m_eFipsFlag = 0x0 m_sLangId = 0 m_pV7LoginRec 0000000000000000: 00000000 00000000 00000000 00000000 00000000 .................... 0000000000000014: 00000000 00000000 00000000 00000000 00000000 .................... 0000000000000028: 00000000 00000000 00000000 00000000 00000000 .................... 000000000000003C: 00000000 00000000 00000000 00000000 00000000 .................... 0000000000000050: 00000000 00000000 00000000 0000 .............. CPhysicalConnection @0x0000000038772240 m_pPhyConn->m_pmo = 0x0000000038772040 m_pPhyConn->m_pNetConn = 0x0000000038772DF0 m_pPhyConn->m_pConnList = 0x0000000038772440 m_pPhyConn->m_pSess = 0x00000000387724C8 m_pPhyConn->m_fTracked = -1 m_pPhyConn->m_cbPacketsize = 4096 m_pPhyConn->m_fMars = 0 m_pPhyConn->m_fKill = 0 CBatch @0x0000000038773370 m_pSess = 0x0000000038772470 m_pConn = 0x0000000038773240 m_cRef = 3 m_rgcRefType[0] = 1 m_rgcRefType[1] = 1 m_rgcRefType[2] = 1 m_rgcRefType[3] = 0 m_rgcRefType[4] = 0 m_pTask = 0x000000003868F468 EXCEPT (null) @0x000000004AD8F240 exc_number = 0 exc_severity = 0 exc_func = sqllang.dll!0x00007FFD60863940 Task @0x000000003868F468 CPU Ticks used (ms) = 31 Task State = 4 WAITINFO_INTERNAL: WaitResource = 0x0000000000000000 WAITINFO_INTERNAL: WaitType = 0x20000CA WAITINFO_INTERNAL: WaitSpinlock = 0x0000000000000000 SchedulerId = 0x1 ThreadId = 0xb60 m_state = 0 m_eAbortSev = 0 EC @0x000000003875E9A0 spid = 0 ecid = 0 ec_stat = 0x0 ec_stat2 = 0x0 ec_atomic = 0x0 ecType = 0 __pSETLS = 0x00000000387732B0 __pSEParams = 0x0000000038773500 SEInternalTLS @0x00000000387732B0 m_flags = 0 m_TLSstatus = 3 m_owningTask = 0x00000000336CB088 m_activeHeapDatasetList = 0x00000000387732B0 m_activeIndexDatasetList = 0x00000000387732C0 m_pDbccContext = 0x0000000000000000 m_pAllocFileLimit = 0x0000000000000000 m_dekInstanceIndex = 0x-1 m_pImbiContext = 0x0000000000000000 SEParams @0x0000000038773500 m_lockTimeout = -1 m_isoLevel = 4096 m_logDontReplicate = 0 m_neverReplicate = 0 m_XactWorkspace = 0x000000003A158040 m_execStats = 0x000000003A877780 CCompExecCtxtBasic @0x000000003875E040 CConnection @0x0000000038773240 CNetConnection @0x0000000038772DF0 m_pNetConn->status = 8 m_pNetConn->bNewPacket = 0 m_pNetConn->fClose = 0 m_pNetConn->pmo = 0x0000000038772040 m_pNetConn->m_lConnId = 0 client threadId = 0x38f11827 m_pNetConn->m_pFirstInputBuffer 0000000000000000: 16000000 12000000 02000000 00000000 00000100 .................... 0000000000000014: 00007700 61006900 74006600 6f007200 20006400 ..w.a.i.t.f.o.r. .d. 0000000000000028: 65006c00 61007900 20002700 30003100 3a003000 e.l.a.y. .'.0.1.:.0. 000000000000003C: 30003a00 30003000 27003b00 0d000a00 0.:.0.0.'.;..... m_pNetConn->srvio.outbuff 0000000000000000: 04010025 00350100 e40b0000 00030000 0001fe04 ...%.5..ä.........þ. 0000000000000014: 00000000 fd0000f3 00000000 00000000 00000000 ....ý..ó............ ... and so on - this is rather long. CUEnvTransient @0x000000003875E0B8 m_ululRowcount = 0 m_cidLastOpen = 0 m_lFetchStat = 0 m_lRetStat = 0 m_lLastError = 0 m_lPrevError = 0 m_cNestLevel = 0 m_lHoldRand1 = 0 m_lHoldRand2 = 0 m_cbContextInfo = 0 m_rgbContextInfo = 000000003875E280 CDbAndSetOpts @0x000000003875E0D8 m_fHasDbRef = 0 m_fDateFirstSet = 0 m_fDateFormatSet = 0 m_lUserOpt1 = 0x14817000 m_lUserOpt2 = 0x40 m_lUserOpt1SetMask = 0xfffff7f7 m_idtInsert.objid = 0 m_idtInsert.state = 0 m_idtInsert.dbid = 0 m_llRowcnt = 0 m_lStatList = 0 m_lTextSize = 2147483647 m_lOffsets = 0x0 m_ulLockTimeout = 4294967295 m_ulQueryGov = 0 m_eDtFmt = 1 m_eDayDateFirst = 7 m_eDdLckPri = 0 m_eIsoLvl = 2 m_eFipsFlag = 0x0 m_sLangId = 0 CExecLvlIntCtxt @0x000000003875E330 m_pBatch = 0x0000000038773370 m_pxlvl = 0x000000003875F800 m_pOAInfo = 0x0000000000000000 m_pOAUnInitFunc = 0x0000000000000000 m_pXPUserData = 0x0000000000000000 m_pRpcInfo = 0x0000000000000000 m_pSharedRpcInfo = 0x0000000000000000 m_pCeiInfo = 0x0000000000000000 m_etts = 0x00000000 m_eQueryProps = 00000000 m_ulNotificationSweeperMode = 0 m_MsqlXactYieldMode = 2 m_dbidPubExec = 0 m_pBulkCtx = 0x0000000000000000 m_pBulkImp = 0x0000000000000000 m_pInsExec = 0x0000000000000000 m_pbhfdCurrentlyActive = 0x000000003875E438 IBHFDispenser @0x000000003875E438 m_pbhfdPrev = 0x0000000000000000 m_pbhf = 0x0000000000000000 m_bErrAction = 0 m_ulStmtId = 0 m_ulCompStmtId = 1 m_pShowplanTable = 0x0000000000000000 m_pShowplanXMLCtxt = 0x0000000000000000 m_pStmtAlterTable = 0x0000000000000000 m_pxliStackTop = 0x000000003875F9E0 m_pqni = 0x0000000000000000 m_ullTransactionDescriptor = 0 m_dwOpenResultSetCount = 1 m_InternalFlags = 0x00001002 CExecLvlRepresentation @0x000000003875F890 CStmtCurState @0x000000004AD8E670 DBCC execution completed. If DBCC printed error messages, contact your system administrator.
First observation: this is a treasure trove, or perhaps a garbage dump. Second observation: the output could actually get a lot more verbose, depending on what the session under scrutiny is doing.
All in all, the fact of its inclusion in dump files tells us that it contains useful information to support personnel, and helps to add context in a crash investigation.
A glimpse of the object tree
You certainly can’t accuse DBCC TEC of being easy on the eyes. But with a bit of digging (my homework, not yours) it helps to piece together how some classes fit together, tying up tasks, sessions and execution contexts.
Recall that Part 5 demonstrated how one can find the CSession for a given thread. DBCC TEC walks this relationship in the other direction, by deriving tasks and threads – among other things – from sessions.
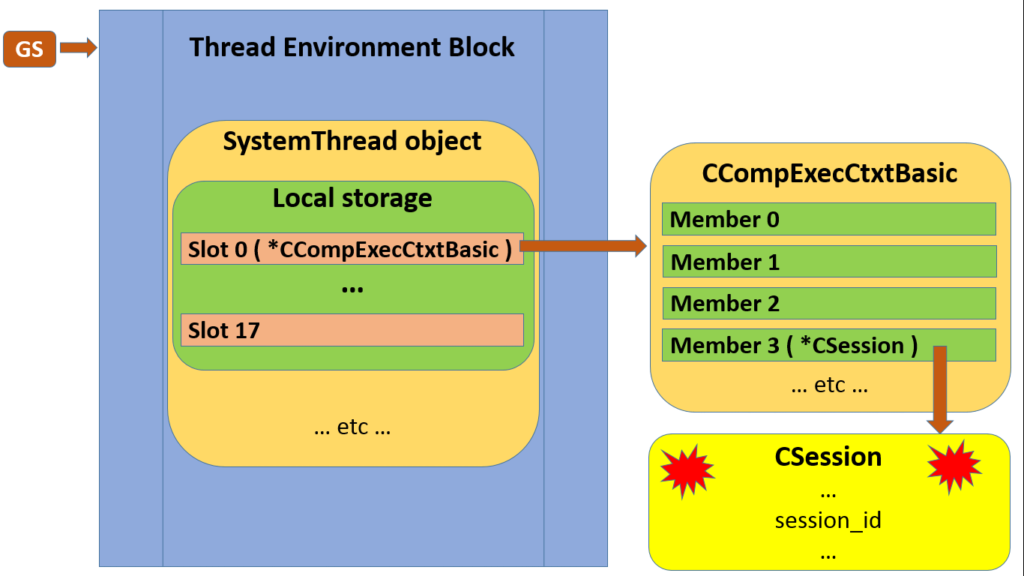
While this isn’t made obvious in the text dump, below diagram illustrates the classes involved, and their linkages.
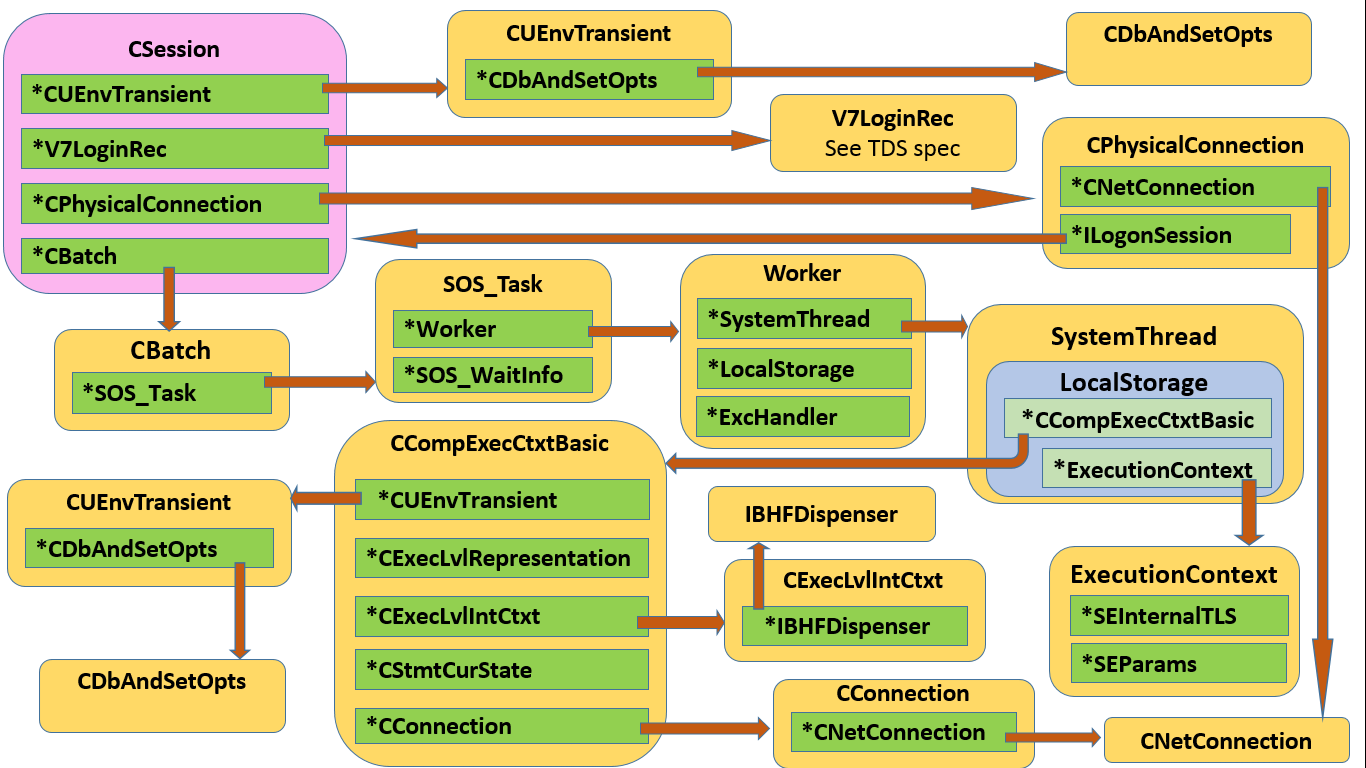
Of course these are very chunky classes, and I’m only including a few members of interest, but you should get the idea.
Observations on DBCC TEC and class relationships
Let’s stick to a few interesting tidbits. CSession is the Big Daddy, and it executes CBatches. Although we’d normally only see a single batch, under MARS there can be more; this manifests by the session actually having a linked list of batches, even though normally the list would contain a single item (I simplified to a scalar on the diagram).
A session keeps state and settings within a CUEnvTransient, which in turn refers to a CDbAndSetOpts. You should recognise many of those attributes from the flattened model we see in DMVs.
However, to make it more interesting, a task (indirectly) has its own CUenvTransient; this is one reflection on the difference between batch-scoped and session-scoped state. And on top of that, even a session actually has two of them, with the ability to revert to a saved copy.
Although a CBatch may execute CStatements, we don’t see this here. The actual work done by a batch is of course expressed as a SOS_Task, which is a generic SQLOS object with no knowledge of SQL Server.
At this point the DBCC output layout is a bit misleading. Where we see EXCEPT (null) it is SOS_Task state being dumped, and we’re not within the CBatch anymore. However, the SOS_Task is actually just the public interface that SQLOS presents to SQL Server, and some of the state it presents live in the associated Worker. The exception information lives within an ExcHandler pointed to by the Worker, and things like CPU Ticks used come directly from the Worker. Task State is the same rather convoluted derivation exposed in sys.dm_os_tasks, as outlined in Worker, Task, Request and Session state. ThreadID is an attribute of the SystemThread pointed to by the task’s Worker, and similarly SchedulerID comes indirectly via the Task’s SOS_Scheduler.
WAITINFO_INTERNAL and (where applicable) WAITINFO_EXTERNAL describe cooperative and preemptive waits respectively. The latter can actually get nested, giving us a little stack of waits, as described in Going Preemptive.
Now we start peering deeper into the task, or rather through it into its associated worker’s LocalStorage as described in Part 5. The first two slots, respectively pointing to a CCompExecCtxtBasic and an ExecutionContext, have their contents dumped at this point.
The ExecutionContext points to one instance each of SEInternalTLS and SEParams. Pause here for a moment while I mess with your mind: should the task in question be executing a DBCC command, for instance DBCC TEC, the m_pDbccContext within the SEInternalTLS will be pointing to a structure that gives DBCC its own sense of context.
Another fun observation: while SEInternalTLS claims with a straight face to have an m_owningTask member, I call bull on that one. Probably it did in the past, and some poor developer was required to keep exposing something semi-meaningful, but the address reported is the address of the ambient task, i.e. the one running DBCC TEC. The idea of ownership is simply not modelled in the class.
Then (still down in the LocalStorage of a Task performed by the Batch under scrutiny) we get the CCompExecCtxtBasic we saw in Part 5. This now shows us a few more members, starting with a CConnection which in turn points to a CNetConnection getting its buffers dumped for out viewing pleasure. This CConnection is in fact the same one pointed to directly by the Batch as m_pConn.
Now, as already mentioned, we see the CUEnvTransient with associated CDbAndSetOpts belonging to the task at hand (through its Worker’s LocalStorage->CCompExecCtxtBasic).
The next CCompExecCtxtBasic member is a pointer to a CEvevLvlIntCtxt which in turn references an IBHFDispenser; in case you’re wondering, BHF stands for BlobHandleFactory, but I’m not going to spill the beans on that yet, because I am fresh out of beans.
Finally, CCompExecCtxtBasic’s performance ends with the duo of CExecLvlRepresentation and a CStmtCurState, neither of whom has much to say.
Whew. That was the superficial version.
Are we all on the same page?
While we could spend a lot of time on what all these classes really do, that feels like material for multiple separate blog posts. Let’s finish off by looking at the pretty memory layout.
Recall that addresses on an 8k SQLOS page will cover ranges ending in 0000 – 1FFF, 2000 – 3FFF, 4000 – 5FFF etc, and that all addresses within a single such page will have been allocated by the same memory object. Now note that the objects which expose a pmo (pointer to memory object) all point to 0x38772040. This sits on (and manages) a page stretching from 0x38772000 to 0x38773FFF.
Have a look through those object addresses now. Do you see how many of them live on that page? This is a great example of memory locality in action. If a standard library’s heap allocation was used, those addresses would be all over the place. Instead, we see that the memory was allocated, and the objects instantiated, with a clear sense of family membership, even though the objects are notionally independent entities.
As a final note on the subject of memory addresses, the eagle-eyed may have noticed that the CPhysicalConnection has a m_pSess pointer which is close to, but not equal to the address of the CSession at the top of the object tree. This is because it is an ILogonSession interface pointer to this CSession instance, with the interface’s vftable living at an offset of 0x58 within the CSession class. See Part 3 for more background.
Further reading
Go on and re-read Remus Rusanu’s excellent How SQL Server executes a query. If you’ve never read it, do so now – it’s both broad and deep, and you can trust Remus on the details.
While reading it, see in how many places you can replace e.g. “Session” with “CSession”, and you will be that bit closer to Remus’s source code-flavoured subtext.