
One of Slava Oks’s classic posts from the 2005 era is
A new platform layer in SQL Server 2005 to exploit new hardware capabilities and their trends. I have occasionally revisited it as a kind of SQLOS manifesto, and some things which at first I found mystifying have become clearer over the years.
In many ways, it seems that the more recent SQLOSv2/SQLPAL work is a simple case of continuing with a project that has been organically evolving since the SQL Server 7 User Mode Scheduler, and rooted in classic Stonebraker: just how far can we assume control of core OS functions within an RDBMS process?
But today I intend focusing on one specific point raised by Slava back in 2005, and running with it a bit:
One of the major SQLOS API’s goals was to eliminate extra memory references that are sometimes referred to as “pointer chasing”. “Pointer chasing” can significantly hurt performance especially when objects allocated on different cache lines or even worse on different OS pages. Having objects on different pages might cause Translation Lookaside Buffer, TLB, misses which are really bad for performance. From the beginning of the project we recognized that SQLOS’s objects are very hot. We have achieved required performance characteristics by keeping object model simple, allocation of objects close to each other and by eliminating virtual functions altogether. These choices have significantly improved SQLOS CPU cache behavior and hence overall performance.
Virtual function calls
Yup, virtual function calls are comparatively rare in SQLOS nowadays. Unless you count memory management, where you can hardly ask for a memory allocation without having to do it through a virtual function call. Oh, and scheduling, where the SOS_Scheduler class is subclassed into ThreadScheduler and FiberScheduler, each containing the implementation of a few functions (e.g. switching between preemptive and cooperative) having completely different “thread” and “fiber” implementations.
But I am not ascending a soapbox to suggest that Slava’s concerns were misplaced. Rather, I’d like to explore what this stuff is all about and why anybody might care. More importantly, I’m going to try and explain something to myself, and you’re welcome to eavesdrop.
Virtual function calls are at the heart of polymorphism in C++ and the backbone of a Volcano-style query optimisation/execution engine. Oddly, the implementation detail is simpler to understand than the high-level theory. As background, invoking a normal function call compiles down to an assembly call instruction with a fixed destination address. So let’s say that the function GetCurrentID() in its compiled form lives at address 0x12345. Wherever it is called from another function, in that function’s compiled form the call will show up as a transfer of control to that known absolute address (in case you care at machine instruction level, I’m ignoring x64’s RIP-relative addressing as something irrelevant to the main point):
call 0x12345
A virtual function call, on the other hand, is only resolved at runtime. The compiler literally does not know what address is going to get called, and neither does the runtime except in the heat of the moment, because that is going to depend on the type of the object instance that the function is called on. Bear with me, I’ll try and simplify.
A C++ object is just a little chunk of memory: a bunch of related instance variables if you like. All objects of the same class have the same structure in this regard. If you’re wondering about functions (a.k.a. methods), these belong to the class, or put differently, to ALL objects of that class. Once compiled, each method is a chunk of memory with a known address, containing the compiled instructions.
Now when a class contain virtual function calls, objects of that class gain a hidden instance variable known as the virtual function table or vftable. This is a pointer to an array of function pointers, each one containing the address of a virtual function. Normally you’ll find this right at the start of the class layout, so the address of the object is also the address of the vftable if one is present. Keeping track of which array entry belongs to which method is one of the chores compilers quietly and uncomplainingly do behind our backs.
Here then is the vftable for the ThreadScheduler subclass as dumped in Windbg. Keep in mind that those lovely function names are thanks to public symbols, and that they are really just human-readable aliases for function pointers (addresses):
sqldk!ThreadScheduler::StartNextWorker sqldk!ThreadScheduler::SwitchPreemptive sqldk!ThreadScheduler::SwitchNonPreemptive sqldk!SOS_Scheduler::SwitchLazyPreemptive sqldk!SOS_Scheduler::SwitchNonPreemptiveIfLazyPreemptive sqldk!ThreadScheduler::Start sqldk!ThreadScheduler::Stop
Out of interest, note that two were inherited from the base class SOS_Scheduler. The vftable for the sibling class FiberScheduler has FiberScheduler-specific variations for all of these functions, including the two that ThreadScheduler inherited from the base class.
So what this all means is that the very first member of an SOS_Scheduler is a pointer to the vftable of either the ThreadScheduler or FiberScheduler class. Calling code can invoke those methods polymorphically without knowing the subclass, because a call to e.g. SwitchNonPreemptive will just compile into a call to whatever address is stored at the third entry of the vftable. And this is exactly what we see in an example at the end of the function sqlmin!SOS_Task::SwitchToNonPreemptiveMode(). I have removed irrelevant detail – the only salient thing is that the ambient scheduler’s address is in the rcx register at the start of the extract:
... mov rax, qword ptr [rcx] jmp qword ptr [rax+10h]
In English:
- Put the contents of the 64-bit value pointed to by rcx (which we know to be the scheduler instance’s vtable address) in rax.
- Retrieve the 64-bit value 16 bytes into the vtable – i.e. the third array entry – and taking it to be an address, go to that address. (That jmp is notionally a call, but it’s the last instruction of the function and hence the compiler can implement the tail call as a goto.)
Now we’re getting a sense of what Slava was on about: instead of making a beeline for a known address, calling a virtual function involves faffing around with two extra layers of indirection, each requiring a memory read. For objects where there are only a few instances, this may be acceptable if the memory lookups stay hot in cache and TLB. Bonus points if the targets share cache lines or at least pages, but if you instantiate large collections of objects and call virtual functions on them, you may waste a lot of CPU cycles in memory stall purgatory.
Indirection indigestion
Oh, but dear reader, a virtual function call is no more than an angel hiccup compared to the nine circles of indirection you find when a Windows API call is invoked with great grinding of gears and clamor of rusty cymbals.
Staying in well-worn territory, I present to you what happens once SOS_Scheduler::Switch() reaches the moment it calls SignalObjectAndWait(). This is only the preamble, before we teleport through the pearly gates of kernel mode where the true action happens:
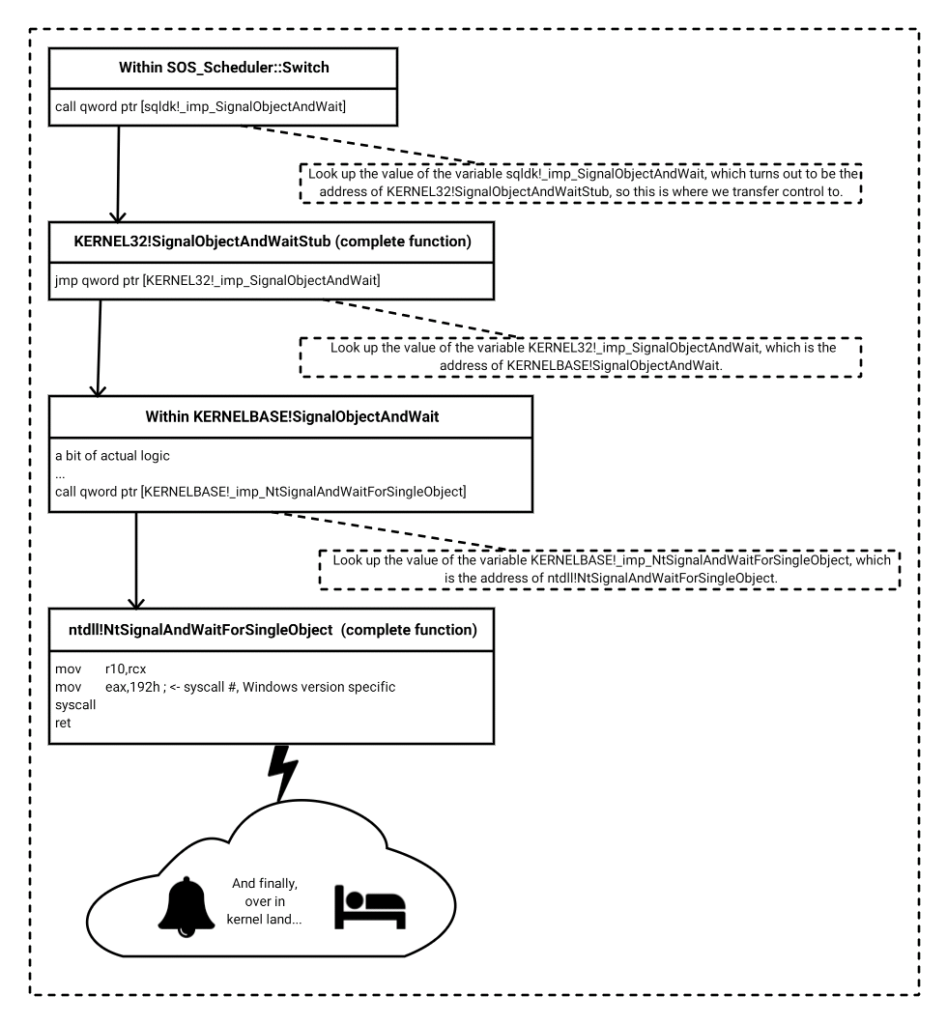
What you are seeing here isn’t anything peculiar to SQL Server or SQLOS, but just reflects the realities of function resolution when you do dynamic linking, plus the legacy of Windows NT design decisions made in the early 1990s. And this call chain has remained unchanged between 2014 and vNext CTP1.1 on Windows.
A few candidate intuitive observations:
- This is grossly overblown and wasteful
- In essence, this indirection presents the same picture as virtual function calls, except worse
- Linus wouldn’t have stood for it
- The SQLPAL folks are slavering at the chance to move their abstractions as high up into that chain as possible
Why this stuff is probably less important than it might appear
Let’s get one thing straight. When you are writing performance critical code in tight inner loops, every cycle counts, and being obsessive about that small surface area of code is absolutely justified. This goes for graphics programming as it does for some Hekaton and columnstore code, and it certainly applies to any number of core SQLOS synchronisation classes I have previously written about – see the 2016 ReaderWriterSpinlock as a good starting point.
However, any body of code running a defined workload can be seen as a heatmap of where time is actually spent (tip of the hat to xperf here). This goes as much for C++ code as it does for a bunch of SQL queries.
Let’s say you have a weekly report that you can tune to cut off a minute of execution time. Worth the cost of a change? I’d venture to say that the answer might depend on how important the recipient wants to feel. Now let’s say you can shave 100 nanoseconds off a function that is called every millisecond. Anything called that often must surely be worth the effort, right? Well, the ratio of call frequency to time savings is nearly exactly the same: there are 10,080 minutes in a week, and there are 10,000 100ns slots in 1ms. I’m not suggesting that this is a great metric, or that 100ns represents the kind of time you could shave off an already well-written function call – just highlighting proportions.
So any code can be said to be full of bottlenecks, assuming you can come up with a workload that makes that code path a bottleneck. Sometimes we create that workload by accident because we’re stupid, and sometimes we actively set out to do it because we’re clever. The stuff that ends up getting tuned under a microscope is likely to reflect real-life workloads, plus a few pet workloads that impress important people and the marketing department.
I’d venture to suggest that the examples of indirection that I’ve been frothing about aren’t particularly consequential, either because modern CPU’s are even more clever than we give them credit for, or because these things only happen in code paths that are not hot enough to worry about in normal workloads.
Staying with the by-now-familiar subject of scheduling though, we do have two data points that show real problems people have grappled with in the past:
- The existence of fiber mode is an acknowledgement that a code path which is normally not hot enough to worry about (in this case the cost of kernel transitions and running OS housekeeping you may prefer to defer) can sometimes get hot enough to warrant running alternative code.
- While the distinction between fiber and thread variations of SOS_Scheduler methods are implemented as virtual functions in a few cases, it is telling that the core act of switching uses conditional branches within a single method rather than vcalls. This is ugly and wrong by conventional object-oriented wisdom, but clearly acknowledges a distrust of vcalls in hot code paths, i.e. right back to Slava’s manifesto.
Postscript: a cup of Joe
I had already started writing this when I read the recent Joe Chang blog post Intel Processor Architecture 2020. Now Joe is one of the cleverest people out there, and his writing never fails to remind me how little I know, but as a side issue to the main post, he made an interesting observation which ties in nicely here if you change the context and squint just right:
Have one or two generations of overlap, for Microsoft and the Linux players make a native micro-op operating system. Then ditch the hardware decoders for X86. Any old code would then run on the Execution Layer, which may not be 100% compatible. But we need a clean break from old baggage or it will sink us.
Off topic, but who thinks legacy baggage is sinking the Windows operating system?
Those layers of indirection I highlighted above would be an example of legacy baggage, as would be the profusion of obscure API calls. Are they sinking Windows? Dunno, and it’s a hard question. SQLPAL is definitely a wonderful evolutionary step in the direction of removing dependence on legacy interfaces and behaviour, as well as implementing a more svelte programming surface. But Joe makes his point in the context of processors themselves implementing a backward-compatible instruction set, setting the stage for asking the same question at many levels up the chain, all the way up to things like “Is SQL as a a language holding us back?” and philosophies of user interface design.
Ultimately, a lot of real-world abstraction is there to support backward compatibility, either already needed or anticipated to be needed in future. In certain shades of light the abstraction is beautiful, but then the light changes and you are overcome by disgust. You just can’t please everybody all the time.
2 thoughts on “Indirection indigestion, virtual function calls and SQLOS”