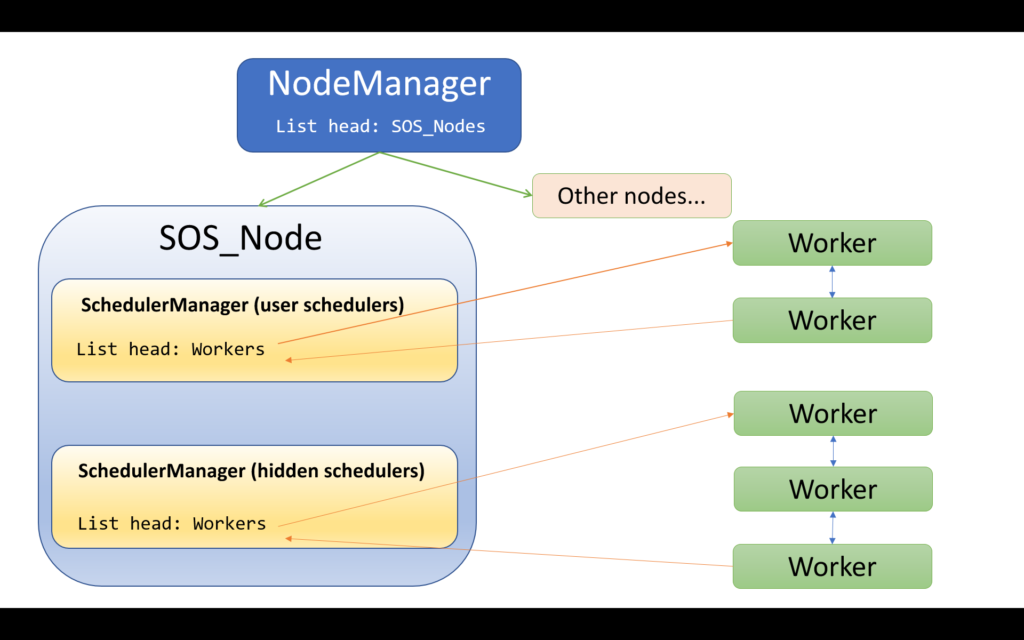
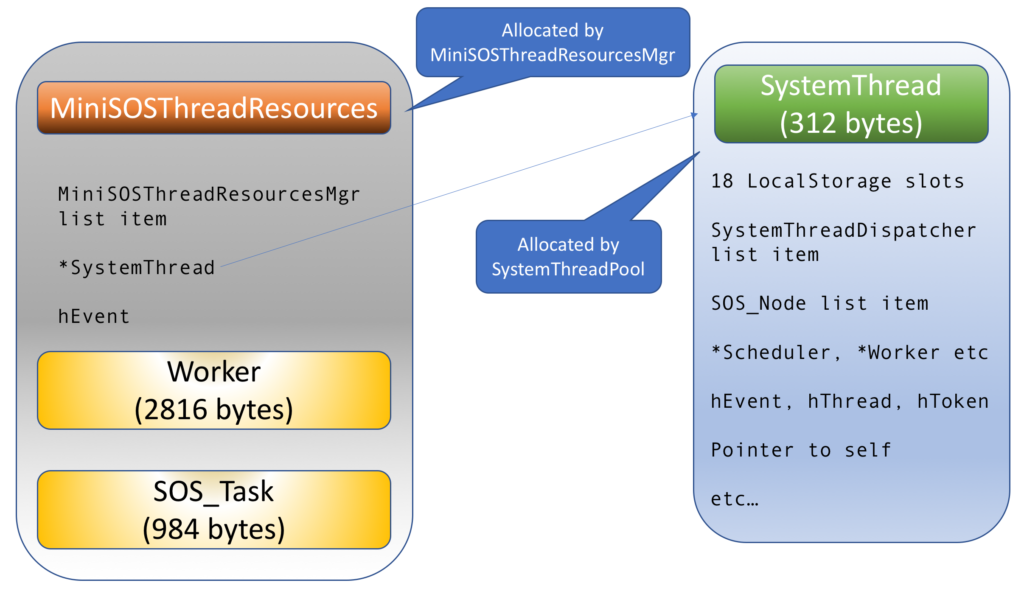
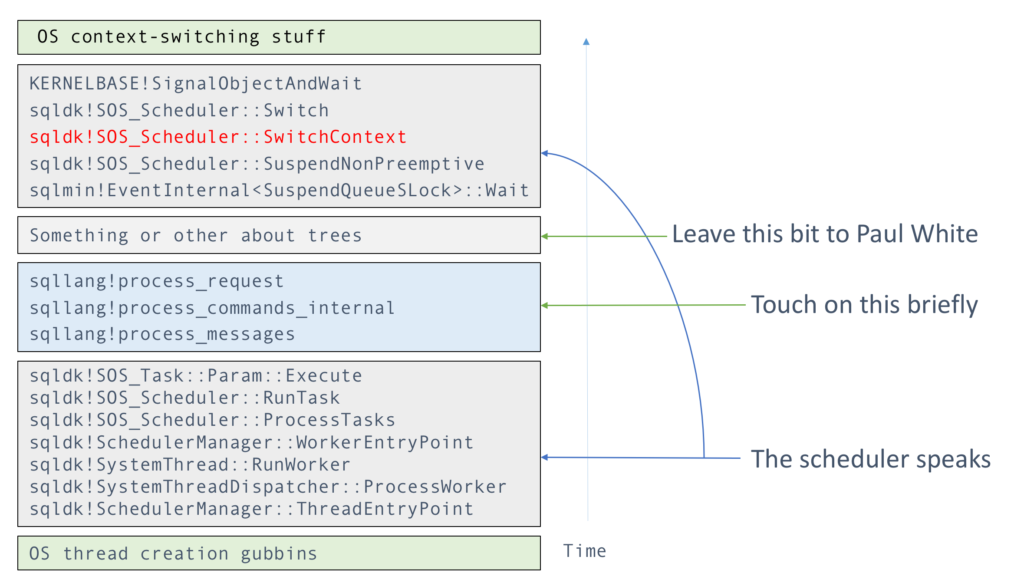
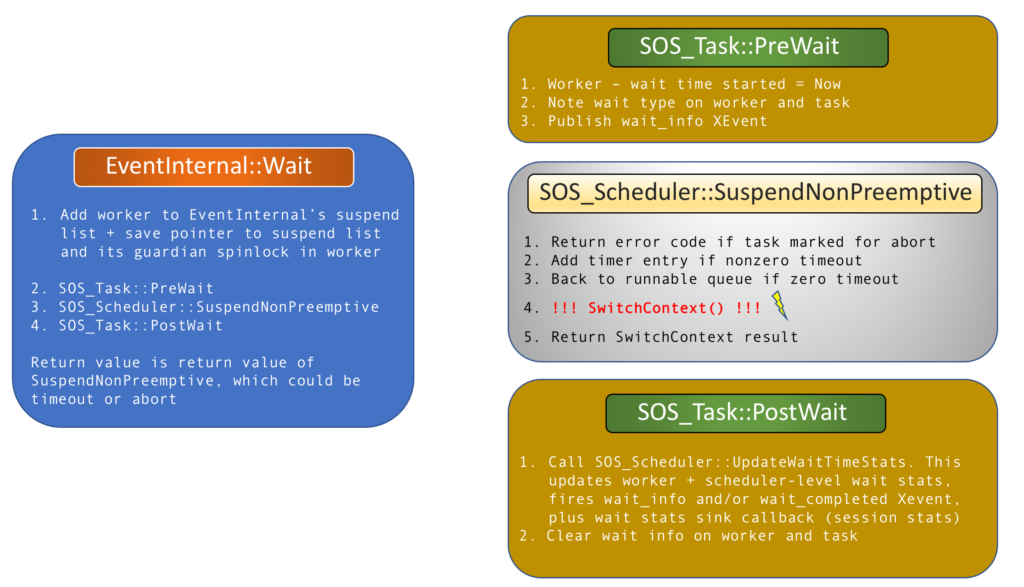
“Who are the folks who made a difference?” I asked two weeks ago. As T-SQL Tuesday themes go, this is pretty touchy-feely stuff, and boy am I glad I went with it, because the #sqlfamily delivered in spades.
Firstly, I want to thank every person who took part. SIXTY TWO blog posts got generated, including a few first-time #tsql2sday contributors as well as first-time bloggers. I am fairly glowing to have been a part of it, and I hope the other contributors are too.
Secondly, from my own experience in writing a post, I know it feels terrible when you start worrying about who to pick. There are many people I could have included, but I hope I have made my appreciation for them clear elsewhere. Not that I want to speak on your behalf, but I’ll assume that the same applies to many other contributors.
In doing this write-up, I made a conscious decision not to hoist named people into this post – I hope you’ll agree that this was a sensible choice. Then again, quite a lot of them appear as participants anyway.
The posts
In no particular order…
Okay, who am I kidding? In firstname-lastname alphabetical order, here is that whopping list of contributions.
Aamir Syed talks about two community leaders who impressed him on two counts: how helpful they’ve been to him, and also how approachable.
Aaron Bertrand reaches back in time to remember people who influenced him during his formative years.
Adam Machanic sings the praises of the old Microsoft Usenet community, drawing the line between that guidance and how it allowed him to become who he is today.
Adrian Buckman gives us a potted history of his route into database administration, and how people impressed, influenced and supported him on that road.
Alex Yates picks the rule of threes, and how he accepted the various nudges from three people who created pivot points in his career.
Alexander Arvidsson makes an eloquent point about paying it forward, and how we take turns standing on each others’ shoulders – I love his reminder that every one of us gets the chance to be a hero to someone.
Andy Leonard paints us the network that has supported him, calling out a few names who particularly inspire him today.
Andy Levy takes the path of reminiscing about inflection points and (by now) old friends, thanking some new friends for letting him into their circle.
Andy Yun has a lovely angle on the challenge, focusing on being inspired by the new generation of data people working their way through professional growth in the community.
Arthur Daniels tells a tale of hands-on guidance by a patient senior hand, also acknowledging well-known community leaders and friends.
Arun Sirpal has had an opportunity for one-to-one mentoring by a well-known name, whose great influence is abundantly clear in Arun’s work.
Bartosz Ratajczyk tells us about having one person draw him into the SQL community, leading to much other useful engagement and personal growth.
Björn Peters gives us another reminder of how a few positive engagements in person or through blogging/social media can draw one into the #sqlfamily.
Bob Pusateri remembers one guy who was clearly a significant point of reference of defining the DBA role, as well as a mentor.
Brent Ozar similarly had one shining beacon, whose example still resonates through Brent’s own teaching.
Chris Hyde went for two community stalwarts, who helped him directly through some well-timed pushes (or were they gentle kicks?).
Chris Jones took his inspiration all the way from childhood, into a recent DBA move into a supportive environment.
Chris Sommer talks about how one PASS Summit session inspired him to move into presenting, and how he has found a comfortable home in the PowerShell tools community.
Chris Yates identifies a handful of specific folks who invested in him, amusingly taking the time to acknowledge the naysayers who made him push himself harder.
Chrissy LeMaire gives us a poignant reminder of the important of representative role models, in addition to working through a number of specific influences.
Cláudio Silva covers a good chunk of his career through specific supportive co-workers, plus some names from the wider data community whose interactions gave him extra impetus.
Craig Porteous scores big on momentum, going full tilt from meeting some lights of the SQL community at SQLbits 2016 to organising an event himself recently. Wow.
Dan Blank has a “thrown into the deep end” story that ended up with him learning about the joys of emergency community help through Twitter (okay, he missed the #sqlhelp hashtag at the time, but it still worked out) and discovering a bunch of other great people along the way.
Dan de Sousa draws the line from a teacher who inspired students to give serious consideration to databases, to more recent peers who form his current support network.
Dave Mason provides a veritable shopping list of people who have helped him along the way, thoughtfully including the community investment made by some companies.
David Fowler traces things back to childhood, through helpful nudges at university and the workplace, also tipping the hat to negative people and environments who made him realise when to call it quits.
Deborah Melkin has a very interesting angle, putting a spotlight on TSQL Tuesday itself – this is indeed a great way to work on your community involvement.
Devon Ramirez talks about how engagement in the workplace led to discovering the wider SQL community and some specific people who have guided her along the way.
Doug Lane reminds us how a single moment (in this case a debut presentation) can be a make-or-break inflection point in personal growth, and how one person’s support there, plus others further along the road, makes all the difference.
Ewald Cress writes about himself in the third person in a pinch, but really enjoyed writing about a teacher, an author/trainer, and some SQL friends.
Frank Gill has a tale about great presentations, and how great community leaders draw you in to become an active participant.
Garland MacNeill takes time out from a cross-country move to list a number of people (and yay! the #sqlhelp hashtag itself!) who have helped him.
Glenda Gable talks about two co-workers and a presenter who provided guidance as she grew into the twin roles of DBA and speaker.
James McGillivray writes about key influences in the regional and international SQL community. Bonus points for being a man who pointedly applauds Women In Tech.
Jason Brimhall has an amazingly eclectic list covering family/friends, sports, and technology, and reminding me that inspiration and guiding forces can come from everywhere.
Jason Squires is one of the first-time bloggers, making me inordinately pleased to have been associated with that genesis. Also, by this point the leitmotif of the PowerShell community drawing people out of their shells is building into a rousing chorus.
Jeff Mlakar took a distinctive approach, eschewing naming individuals in favour of a very thoughtful piece on drawing inspiration from the people and situations around you.
Jen Stirrup paints a familiar picture of feeling out of place at a community event when someone comes along and engages you, keeping you within the circle of warmth. And for the sake of the rest of the community, I for one am very grateful that Jen stayed!
Jim Donahoe goes with the theme of finding kindred spirits at community events, and how the friendships spill over beyond technology.
John Martin calls out some familiar names, and demonstrates what is also becoming a common theme: kindness and support at an early point in someone’s career is something they tend to remember.
John Sterrett talks about paying it forward, from the angle of the guy who eventually pays it back by helping to organise an upcoming SQL Saturday in Wheeling, West Virginia.
Kendra Little gets enthused about adventure, with a refreshing reminder of how people, technology, and personal stories can’t help but get interwoven.
Kenneth Fisher takes the time to higlight several people who have provided him support at important inflection points, as well as on an ongoing basis.
Kevin Hill picks three people (but like me, then squeezes in a fourth) who have been instrumental at different stages of his career.
Lonny Niederstadt also goes for the Rule of Threes, starting with an early influence outside of SQL Server, who evidently played a role in Lonny’s own tenacity in tracking problems across traditional domain boundaries.
Lori Edwards keeps that triplet rhythm going, picking two heroes who influenced her from a distance, and one who took a more active role in her life.
Malathi Mahadevan focuses on the person who took her from the already good starting position of user group leader to SQL Saturday organiser.
Matt Cushing also has a specific guiding light in mind, reminding us of the power of #sqlfamily and social media engagement.
Michelle Haarhues tells her story in terms of pivotal people at various times in her career, once again reminding us all how important female role models and peers are in a healthy, or at least aspiring-to-healthy, workplace.
Mike D Lynn is another first time blogger (welcome!), talking about the support and influences that helped his early career and his growth into SQL Server specialisation.
Mindy Curnutt gives us a glimpse into her fascinating life story through calling out a bunch of people who influenced and helped in various ways. The Bill Butler paragraph alone reads like the synopsis of a movie I’d love to see.
Paul Randal reminds us of some of the many illustrious SQL Server stalwarts he has been associated with, and who helped him along the way. Nice side note about presentation technique too!
Peter Schott takes us back to the Usenet community that Adam Machanic also focused on, additionally emphasising the kind of non-SQL community you can find within the SQL community.
Randolph West highlights one very influential pivot from his earlier career in data, a friend who has passed away since.
Rob Farley has a unique angle, applauding some people who impressed him so much that he hired them.
Rob Sewell just bubbles over with enthusiasm for some of the people he gets to work, present, and organise with. We can all take inspiration lessons from this guy.
Robert L Davis gives us a nicely balanced post involving lessons in both personal development, technology, and workplace culture.
Samir Behara thanks a handful of colleagues who helped get his blogging kick-started, and then turns his attention to one person who helped him grow into a co-chapter lead and SQL Saturday organiser.
Shane O’Neill manages to tell the story of his own growth into blogging and very strong community involvement through the various people who helped him on that journey.
Steve Jones talks about how inspirational it was to see one of his heroes present at the very first PASS Summit – double whammy!
Tamera Clark reminisces about a few interesting turning points in her life, and the ongoing support of #sqlfamily.
Todd Kleinhans sings an ode to print books, the people who write them, the people who used to survive selling them, and the stories locked up in individual copies. Some very interesting thoughts in there.
Wolf calls out quite a few influences, highlighting two people who respectively got him into speaking and into relaxing in his existing personal branding.
In closing
Our data community has deep roots, and contains an amazing network of people. Some of them may appear to live on Mount Olympus, but when you read these stories, you are continually reminded how many of those folks want to help you grow. Embrace those opportunities!