

Talk about serendipity. I’ve been working on a progression of blog posts that would include dealing with the SOS_RWLock in both 2014 and 2016 versions, and today is a perfect excuse to align it with the 2016-themed T-SQL Tuesday hosted by Michael J Swart.
The 2014 incarnation of the SOS_RWLock looked sensible enough, but since we’ve been told it was improved, it’s a great opportunity to see how one goes about tuning a lock algorithm. So with lock-picking tools in hand, follow me to the launch party of the Spring 2016 SQLOS collection to see what the hype is all about. Is the 2014 implementation truly Derelocte?
Class member layout
As before, we are looking at a compact SOS_RWLock class with an accompanying helper structure that represents entries on its wait list; I’ll call the latter WaitListEntry. Here is pretty much everything you need to know about the class layout.
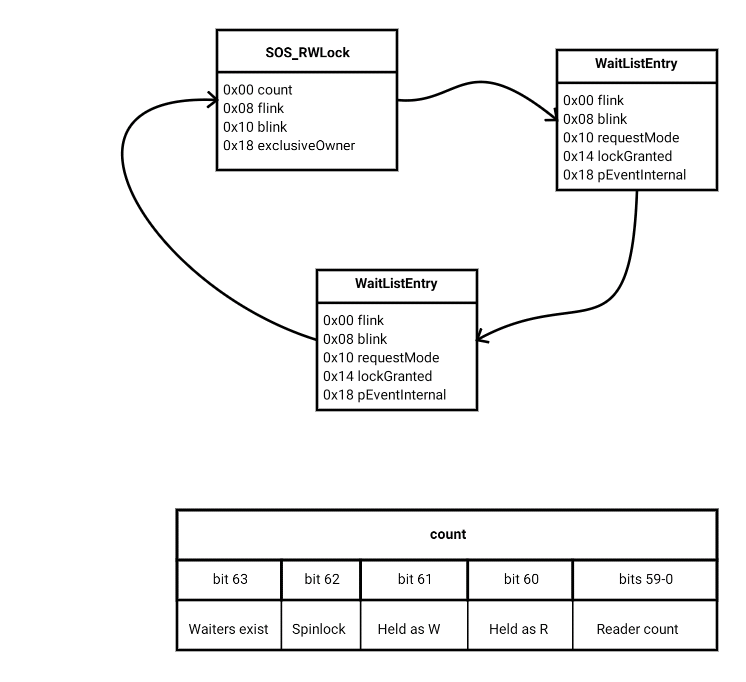
Allow me to call out some layout comparison points against the 2014 version:
- There is no separate member to track the shared reader count.
- The four-byte spinlock is gone.
- The four-byte waiting writer count is gone.
- The two chunks of four-byte padding (for qword alignment of pointers) are gone.
- The WaitListEntry structure hasn’t changed at all.
This boils down to a leaner package: 32 bytes vs its predecessor’s 48 bytes. This already means that it can snugly share a cache line with the thing it protects if the protected part of the latter fits in the remaining 32 bytes of a cache line. But how does it pack in the functionality that was previously supported by the now missing members? The simple answer is that the count member gives us all the synchronisation metadata we need.
A new flavour of spinlock?
A good way to start unravelling the control nybble of the count member is to look at the spinlock bit. The spinlocks we know and love are instances of the Spinlock template class. They implement incremental backoff, their aggregated spin statistics are exposed in sys.dm_os_spinlock_stats, and ownership by a specific thread is trackable. What we have here is an entirely different beast. It doesn’t track ownership, it can spin aggressively without any kind of backoff, and there is no tracking of how much spinning is done on it. It would be nice to call it New And Improved, but to be honest, it is actually a step backwards while simultaneously being an improvement. What gives?
I’d like to imagine that this is a simple case of good engineers getting back to basics. The classic use case for a spinlock is to support very short and efficient critical sections. Building in an exponential backoff algorithm is an admission that the critical section might be longer or more complex than necessary, or of course that the designer of the spinlock is focused on creating a pretty and nicely instrumented lock class rather than a lean inline code path from spinlock acquisition into the critical section and spinlock release.
For the purpose of illustration, let’s pretend we want to make no change to the other 63 bits within Count, and we just need to acquire the spinlock. The code path would look like this in pseudocode:
repeat
{
oldCount = Count with spinlock bit clear
newCount = oldCount with spinlock bit set
}
until compare-and-swap(Count, oldCount, newCount) succeeds
If you’re not comfortable with compare-and-swap (CAS, also called compare-exchange) semantics, it’s worth getting your head around it, because it’s quite simple and incredibly powerful. This processor instruction can be read as “Replace the value of Count with newCount, but only if the value is oldCount at that very moment. Do this all atomically, and tell me if it succeeded, i.e. if the old value of Count was indeed oldCount”.
With that in mind, the above pseudocode implements the logic of setting the spinlock bit to 1 without changing anything else, but only if the spinlock bit is 0 at the time you try and grab it (i.e. someone else hasn’t acquired it) and only if none of the other 63 bits have changed value since we initially read the value of Count. Interestingly, if the spinlock was acquired (belonging to someone else) at the top of the loop, but released by the time we get to the compare-and-swap, we still get it: there was no need to go sulk preemptively in a corner on the premise that it wouldn’t be released by the moment we try to acquire it. If we couldn’t achieve the compare-and-swap, just try again in a loop, starting with a fresh read of the current Count value at the top of the loop, until it succeeds.
This is really a case of optimistic concurrency, albeit potentially confusing since it is being applied to the act of acquiring a pessimistic spinlock! It maps closely to the pattern of keeping a rowversion column in a row that is sent to an application that might update it. Any attempted update by the application must include the rowversion it started off with, and if the row has changed in the meantime (new rowversion in the database) the update attempt fails and the application has to try again. The only real difference is that we don’t use a surrogate rowversion, but the complete “row” (64-bit integer in this case) to check whether we are doing the update from the expected starting position.
So while I have described this in terms of a spinlock bit, the concept extends to anything else you can fit into a single memory access. If you wanted to both acquire the spinlock and increment the reader count, it would be this small variation:
repeat
{
oldCount = Count with spinlock bit clear
newCount = oldCount + spinlock bit set and ++readerCount
}
until compare-and-swap(Count, oldCount, newCount) succeeds
You can do any such updates to a 64-bit structure where you start with the current value, then take your time figuring out what you want the new value to be, and eventually try the compare-and-swap. Obviously the longer you take to determine your new value, the bigger the chance that the CAS will fail due to someone else changing the member value from the old one you started off with, necessitating another walk around the block, but the point is that the structure remains unlocked except for that brief moment during the CAS itself.
The major restriction here is that CAS doesn’t extend beyond a certain word size – 64 bits in our case. If you need to lock a structure bigger than 64 bits, you’re back at the requirement for pessimistic locking, i.e. protecting your structure with some form of lock and serialising access to it. This then is the reason for still having a spinlock within the SOS_RWLock: it isn’t needed to protect anything within the Count member, but it protects something that don’t fit inside Count, namely the doubly-linked waiter list.
All in all then, this is still a class that involves an internal spinlock. However, it scores on these counts:
- The spinlock is only taken for the duration of a linked list enqueue or dequeue.
- Its acquisition is very aggressive, meaning that it is unlikely to take long to acquire when contended, as long as the first point holds (the other guy holding the spinlock releases it quickly).
- Because not all state changes to the SOS_RWLock require the spinlock, it isn’t even used except when adding or removing a waiter from the SOS_RWLock’s wait list.
Time to take a look at just how much can be done atomically.
Action-packed compare-and-swap operations
So I was lying through my teeth with the previous example of simultaneously incrementing the reader count and acquiring the spinlock. How come? Well, if you’re incrementing the reader count, that would be because a read request is being granted, and – wait for it – this is a spinlock-free operation! Let’s walk through this example as found in GetLongWait().
Remember that this is all a trick based on agility. We start with a snapshot of the opening state of the Count member, we calculate what we want Count to be, and then we perform the CAS attempt against the (optionally modified) expected opening state of Count. If someone pulled the rug out from under our feet during the process, we try again, starting from a fresh Count snapshot.
In order to be granted a read request, there are some preconditions:
- The SOS_RWLock must not currently (at the moment of CAS) be held in Write mode, i.e. it must either be unacquired or already held in Read mode.
- Even if currently held in Read mode, the new request will be forced to wait if there are any waiting writers. This can be simplified to “if there are any waiters” since the presence of waiters while the lock is held in Read mode implies that there is at least one writer in there – refer to the 2014 explanation for the acquisition rules.
- This one is shining in its absence, so I want to call it out: amazingly, as long as the other two preconditions are met, it makes no difference whether or not the spinlock is held at the moment of CAS, because we aren’t going to be touching the waiter list.
Assuming success, the post-acquisition state will be as follows:
- The held mode will be set to Read
- The reader count will be incremented by one
This Read acquisition path of GetLongWait() works as follows. In this pseudocode, taken from within the CAS retry loop, EOC is the “expected old Count” value, initialised by reading the current value of Count, but optionally getting modified before being used as CAS input, and NC is the New Count value that the CAS will replace Count with if its value is EOC at that instant:
if EOC.heldAsW or EOC.waitersExist {
if EOC.spinlock {
pause
break //back to top of loop
}
AboutToWait = true
NC = EOC with waitersExist and spinlock set
} else {
NC = EOC.readerCount + 1 + heldAsRead
}
The “pause” above is literally a processor pause instruction, the same one that is looped over for a traditional SQLOS spinlock between acquisition attempts; it serves to nudge the processor into giving a bit of extra love to the other hyperthread on the core, wasting just that tiny hiccup of time for our thread which has nothing better to do at that moment.
The Write acquisition path is simpler, and in the contended case falls through into the same wait logic as the Read option. This wait code path is essentially the same as the 2014 version: if a wait is needed, we arrive here out of the CAS loop with the spinlock acquired, so it’s just a case of linking the WaitListEntry (again a local variable) into the wait list, releasing the spinlock and sinking into the warm embrace of EventInternal<SuspendQSlock>::Wait().
If either Read or Write request succeeded immediately, the method can exit and life goes on for the happy lock acquirer, all with precious little time wasted in the acquisition, and with minimal chance of disrupting things for others.
This is phenomenally compact stuff. I’d like to emphasise how the spinlock is only necessary to protect the wait list, hence there is no need to involve it when it is known that the request can be granted immediately. Even for the Write case, where a further non-atomic update to the ExclusiveOwner member is needed, this can be done separately at leisure after the CAS, because in a sense the address of the owning worker is only a memo item, as opposed to being the primary indicator whether or not the lock is currently acquired in Write mode. Nobody else is going to overwrite it or make a decision based on its value between the count update and the exclusiveOwner update.
Other optimisations
The ReleaseLock() method has also been the target of an interesting little optimisation apart from its similar CAS pattern. In the 2014 version, it takes no parameters, but the 2016 incarnation requires the caller to specify what mode it is holding the lock in. (Update: I since found that the parameter exists in 2014 and is supplied by the caller, but then the method ignores it. This may reflect a state of the code that is essentially in-between versions.)
Now this isn’t logically necessary: obviously the lock itself knows what mode it was being held in. However, having it specified by the caller means it doesn’t need to make decisions based on something held in Count at the outset. This goes hand in hand with having separate branches for Read release and Write release; while the total byte count is slightly higher, it removes some conditional logic beyond the R/W split, and this is itself an optimisation by taking away an opportunity for branch misprediction. Turning it into a familiar analogy, it is very much a parameter sniffing problem, in that the CPU has different optimal “execution plans” for the R and W cases.
Finally, we are now starting to see use of explicit prefetching, where we give the CPU forewarning (a few instructions ahead) that a given cache line will be needed for write access. Some prefetching has been present in the 2014 code base, so it looks like it is a technique reserved for times when you need to pull out all the stops. Again there is a SQL analogy: prefetch instructions are like gentle query hints that don’t make a logical difference to the outcome of the code. Littering your code with them won’t necessarily make it better, but it can make it harder to read, and their use come with an implicit assertion “I know something he CPU/Query Optimiser doesn’t”.
SOS_RWLock’s place in the pantheon
I see the SOS_RWLock as a halfway point between an SOS_Mutex and a storage engine latch. The latch goes a bit further with its multiple acquisition modes, more complex compatibility matrix, and participation in wait tracking under its own set of wait types. As a reminder, there isn’t such a thing as an SOS_RWLock wait type, because any waiting done by it is logged under the heading of whatever came into the SOS_WaitInfo passed into GetLock().
The 2016 rework moves into an interesting direction, getting a lot more lean and stealthy. It loses the trackable SOS_RW spinlock of 2014 and now uses a mechanism where it is theoretically possible to burn a lot of CPU while in a CAS loop, trying to update various members including that spinlock. Now I suspect this simply isn’t an issue in practice, but it is again a lovely creative tradeoff: do you complicate your code to the point of being less efficient for the sake of instrumenting it to quantify that efficiency? This is the kind of scenario where only something like XPerf sampling will show us whether or not CPU is being burned within the synchronisation class.
This also makes me a bit sorry for the poor old latch class. Clearly the hype of recent years around Hekaton has turned the word “latch” into something toxic to marketing-minded folks. Re-read this politically correct sentence from the “It just runs faster” blog post: “SQL Server 2016 contains the design changes for the SOS_RWLock using similar design patterns and concepts leveraged by in-memory optimized objects.”
Funny thing is, if I didn’t know about Hekaton, I would have sworn that much of the implementation inspiration comes from the good old latch design as laid bare by Bob Ward six years ago. So maybe I twisted your arm a bit by labeling that 64-bit member “Count”, but I do feel that the storage engine latch is the true parent here.
Further reading
Klaus Aschenbrenner has written a nice post describing lock-free data structures . It is always worth looking at this stuff from as many angles as possible.
5 thoughts on “Unsung SQLOS: the 2016 SOS_RWLock”